Qwen 3:新的开源标准
一次惊艳的发布:基础模型、推理引擎、多规模模型,赶在LlamaCon之前悉数登场


阿里巴巴期待已久的 Qwen 3 开源模型套件 终于发布,完美地满足了一个强大开源发布的所有条件:极高的基准测试分数、多样化的模型尺寸、推理能力的开关,以及宽松的许可证(博客文章,Artifacts)。2025 年无疑是自 ChatGPT 推出以来,使用开源模型进行构建的最佳年份。
Qwen 3 模型的得分如此出色,以至于我们现在可以看到关于 Qwen 模型是否具备 DeepSeek R1 等近期前沿模型的个性和持久力的讨论。这是一个重大的成就——这是大量计算和人员投资的直接结果。
模型发布概览
Qwen 发布了 6 个指令模型 及其基础版本和量化变体,包括:
- 两个稀疏专家混合(MoE)模型:
- Qwen3-235B-A22B
- Qwen3-30B-A3B
这两个模型的稀疏性因子与 DeepSeek 的 MoE 架构相似。
- 六个密集模型,带有 Apache 许可证,参数分别为:
- 32B、14B、8B、4B、1.7B 和 0.6B。
作为参考,最小的 Llama 4 模型仍有 109B 参数,而 32B 范围 因其在开源模型用户中的受欢迎程度而闻名!
基准测试表现
以下是完全训练的、最大模型的基准测试结果(注意,它们未与一些近期模型如 o3 进行比较)。评估可能都在开启思考模式并使用最大 token 数的情况下进行(未记录)。
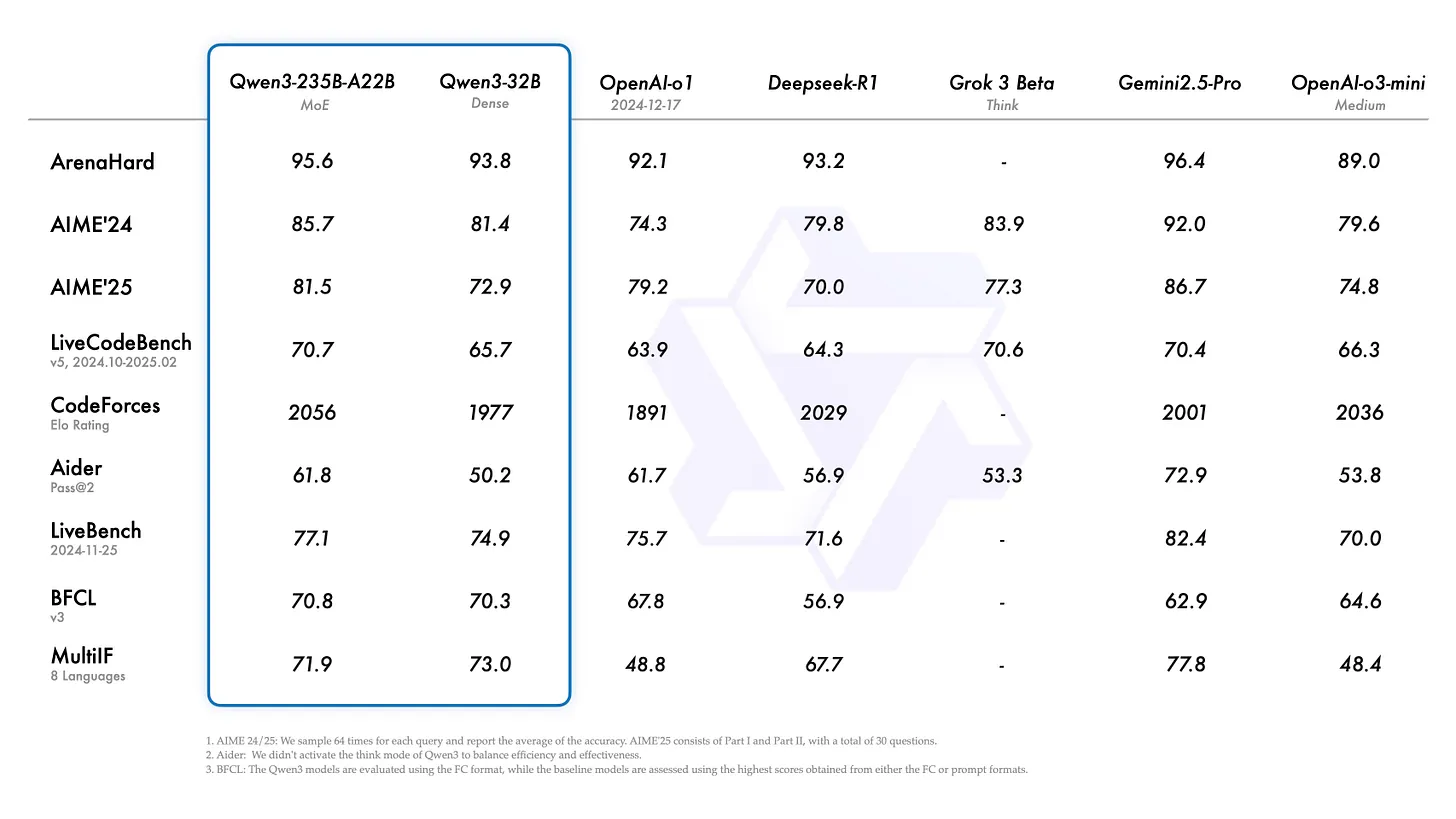
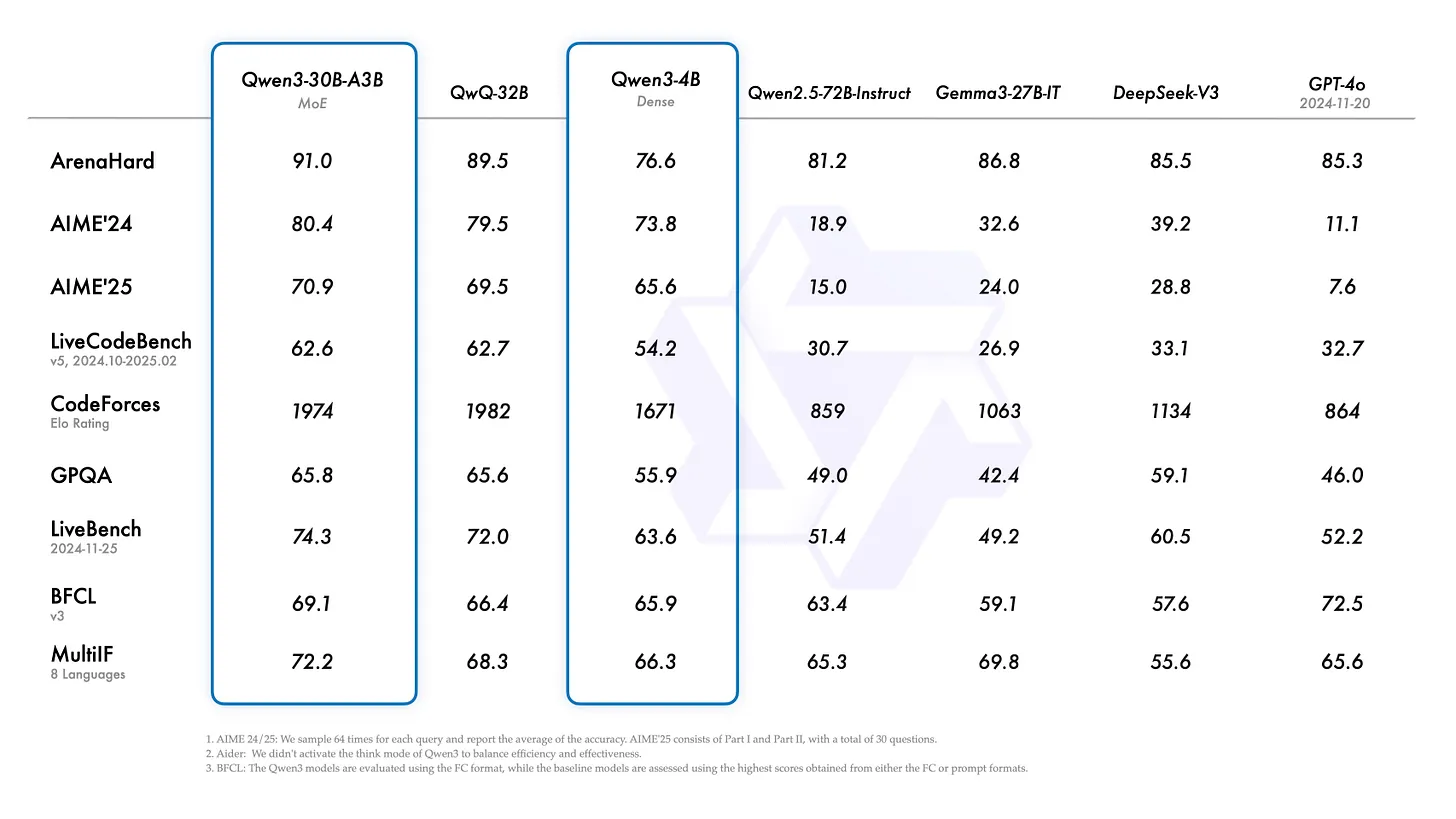
较小模型的得分也非常出色。一个 4B 密集模型 能与 GPT-4 或 DeepSeek V3 同台竞技,简直令人难以置信。
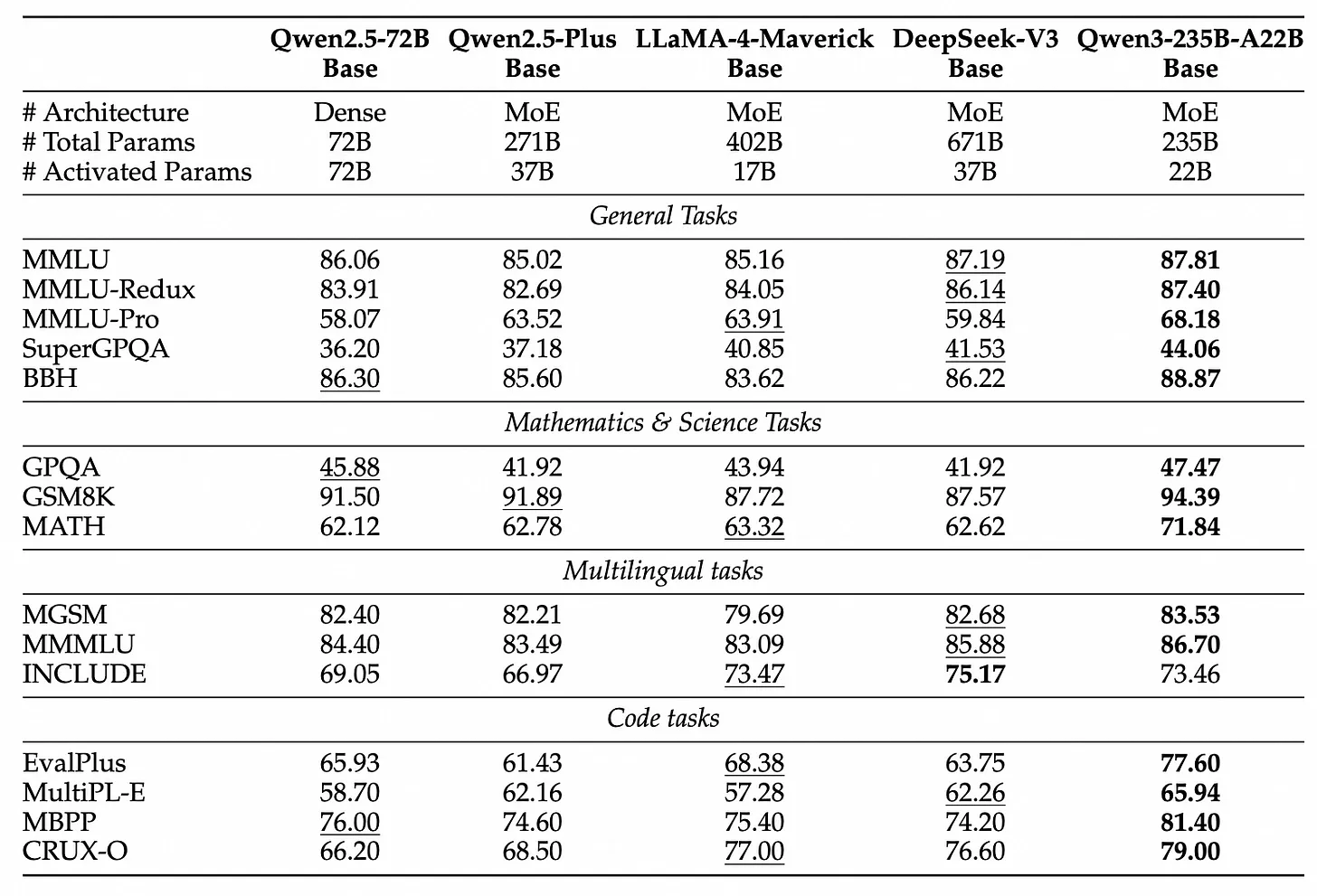
Qwen 团队提供的基础模型评估显示,领先的基础模型如 Llama 4、DeepSeek V3 和 Qwen 之间的得分相似性:
模型差异的关键:后训练
目前,模型之间的区别主要在于 后训练,特别是通过推理时计算启用推理能力,这可以将评估得分从 40% 提升到 80%。上图中“基础模型”的定义也较为混乱,因为这些模型在训练过程中接触了指令和推理数据,以便为后训练做准备。
没有研究实验室公开研究过什么使基础模型对下游后训练有用,因此可以假设这些实验室都在调整预训练以满足自己的后训练需求,而不是专门满足开源社区的需求(当然,我们从中受益)。
当 Llama 4 不可避免地发布推理模型时(可能就在明天),它们将突然再次显得重要。推理模型与非推理模型的这种差异使得跟踪这些发布变得更加困难。所有 Qwen 3 模型的得分都是推理模型,这使它们看起来非常强大。
后训练方法
我的大部分分析依赖于他们使用的后训练方法,这与 DeepSeek R1 配方 非常接近:
- SFT 训练:培养 CoT(Chain of Thought,思维链)行为。
- 大规模推理 RL 阶段。
- 传统的偏好 RL。
这种方法仅适用于两个“前沿”模型:Qwen3-235B-A22B 和 Qwen3-32B。
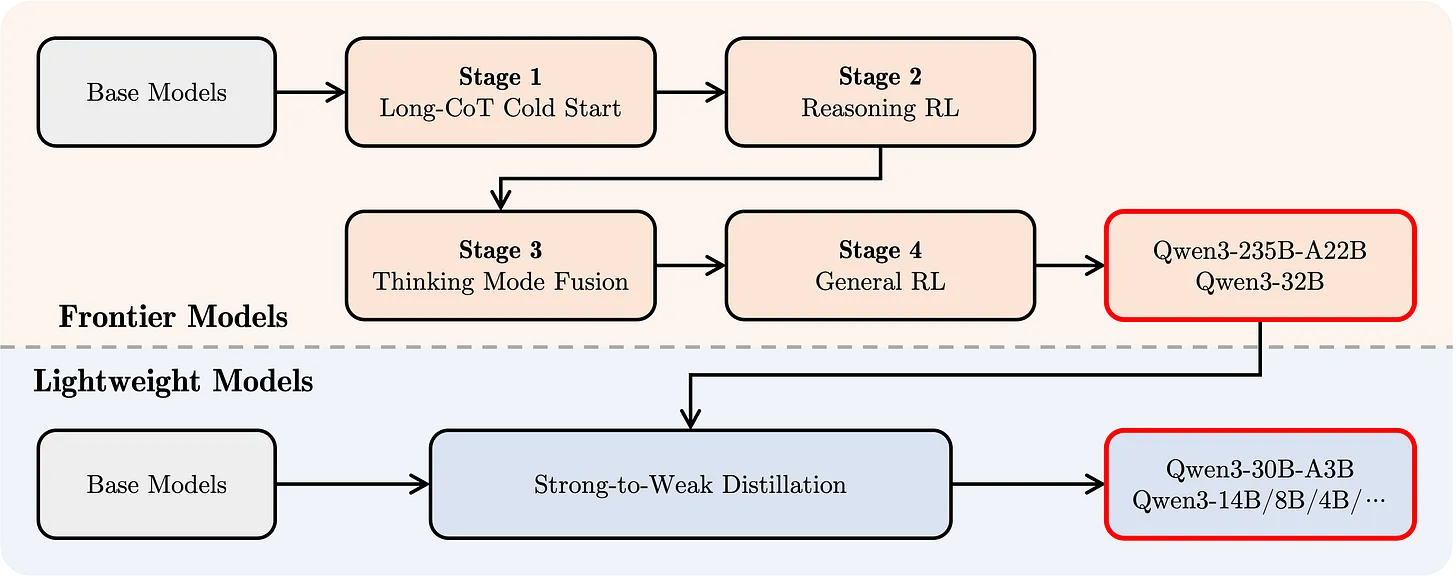
其他较小的模型则经历了所谓的 “强到弱蒸馏”。这种方法未明确记录,但可能主要涉及在大量合成数据上进行指令/SFT 调优,这些数据来自他们较大的模型。这种以 SFT 为重点的蒸馏可能会创建在基准测试上非常强大的模型,但在更广泛的任务领域中可能不够稳健。需要更多测试来确定,而因为我们有基础模型,更多人将对这些模型应用他们自己的后训练堆栈!
他们的后训练技术包括 思考开关,正如我们在 Grok 3、Claude 3.7 和开源模型如 Nvidia 最近的 Nemotron 发布 中看到的那样。他们通过改变模型的 token 预算创建了非常好的 推理时缩放图。
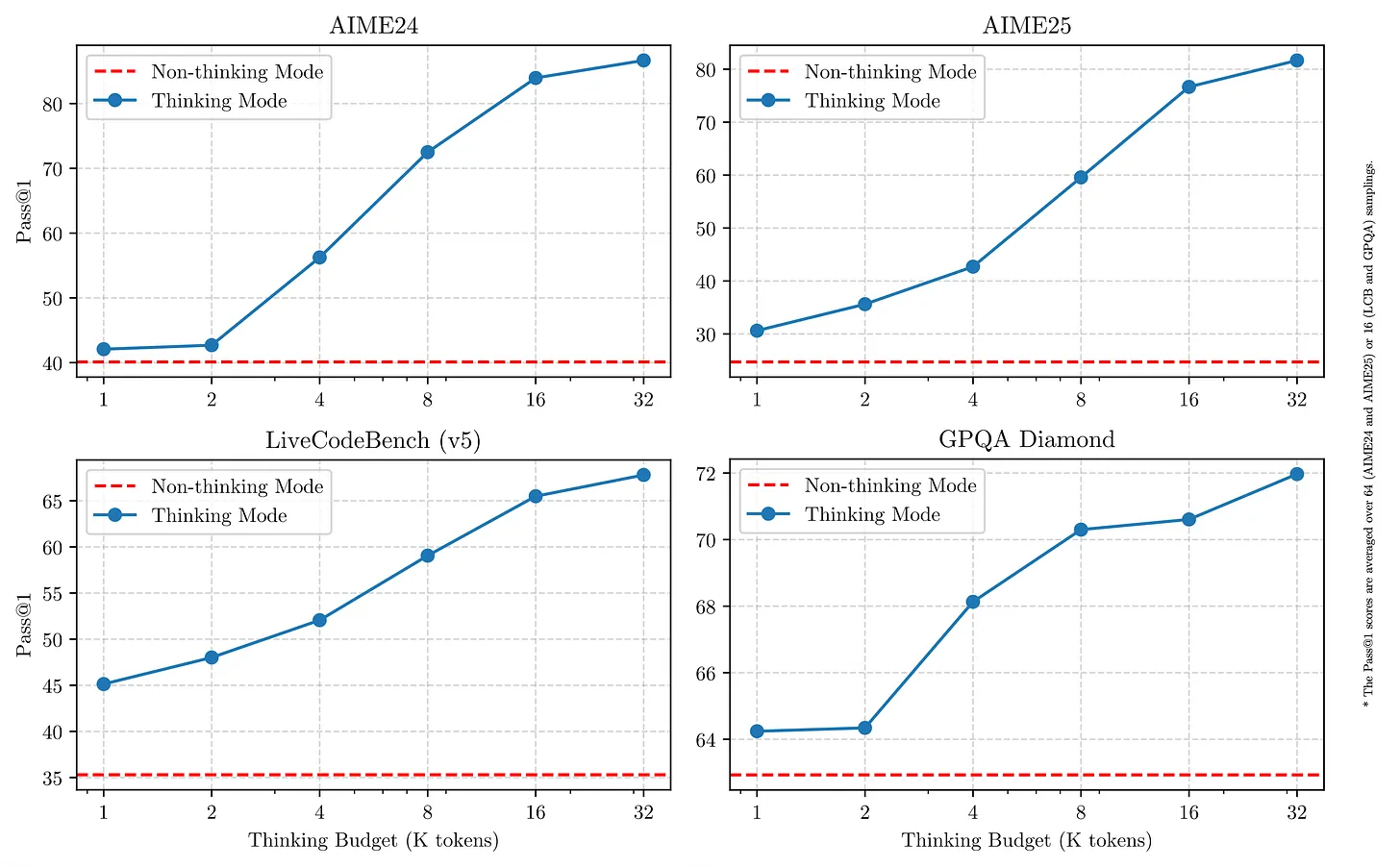
上图中使用的模型未记录,但从得分来看,可能是他们最大的模型 Qwen3-235B-A22B。这些是评估的非常显著的提升!
重点摘要
进入文章的重点摘要部分——我在这里提出的许多问题可能会在未来几周的技术报告中得到解答:
- 这次发布是对 DeepSeek R1 配方和蒸馏 的重大验证。较小的 Qwen 3 模型可能通过更多的 RL 训练进一步改进,正如 DeepSeek 在他们的 R1 报告中讨论的那样。
- 预训练 token 数量惊人(与 Llama 4 预训练 一致,Scout 约为 40T,Maverick 约为 22T 多模态;DeepSeek V3 约为 15T)。Qwen 详细说明他们使用了超过 30T 的一般数据 token 和 5T 的“高质量”数据 token,这比我们在 Ai2 为 OLMo(或其他较小的开源模型工作室)训练的整个预算还要多。
- Qwen 3 不是原生多模态的,因此与 Llama 4 和似乎正在转向早期融合(如 GPT-4o 和可能在 YouTube 上训练)的行业相比,他们可能在这里有所欠缺。社区正在寻找具有工具使用和视觉的模型来制作计算机使用代理。
- Qwen 3 是开源模型的最佳选择——峰值性能和尺寸缩放——DeepSeek 风格或质量的领先模型,但像 Llama 1、2 和 3 一样完全可访问的模型尺寸套件。
- Qwen 3 展示了算法和数据改进如何使模型变得更小。博客文章详细说明了约 50% 的密度改进:“例如,Qwen3-1.7B/4B/8B/14B/32B-Base 的表现与 Qwen2.5-3B/7B/14B/32B/72B-Base 一样好。”
这些数字被夸大了,因为 Qwen 2.5 不是一系列推理模型,而现代后训练在当前流行的评估中实现了疯狂的攀升。 - 在 ICLR 关于开源模型的研讨会小组讨论 中,Qwen 的 Junyang Lin 大致说他们“需要 100 人来制作一个好的通用模型。”
- 许可证非常好,所有较小的模型都是 Apache 2.0,而 Qwen 许可证历来比 Llama 宽松得多。当您微调过去使用 Qwen 构建的模型时,您可以选择您的许可证并在模型文档中添加“使用 Qwen 构建”。
- 开源模型中的 工具使用 非常有趣且难以快速测试。Llama 也有这个功能,这可能是 2025 年开源模型的一个持续主题,值得关注。
- 我们将开始看到 Qwen 是否有品味/氛围。他们已经完成了基准测试,现在我们将看到它们与 R1、o3 和 Gemini 2.5 Pro 等模型在前沿的持久力方面的比较。
从有限的试用和在线阅读我认识的人的反馈来看,这些模型可能不如我们今天习惯的最佳模型稳健。这仍然是一个重大的成就,也是实验室的正常路径——先获得基准测试分数,然后弄清楚如何制作用户喜欢的东西。基准测试的兴奋通常是打开漏斗顶部让人们尝试您的模型的原因,这反过来又会返回有价值的提示和用户数据。
我们需要更多测试来确定! - Qwen 3 是一个 高质量的发布,工具集成在无数开源库中,如 HuggingFace、VLLM、SGLang 等。
- Qwen 的推理链以“Okay,”开始,很像 DeepSeek R1 的。这表明他们使用 R1 来帮助训练他们的模型,鉴于其许可宽松,大多数试图追赶的公司都应该这样做。另一个例子如下:
这真是一个精彩的发布,Qwen 团队应该感到非常自豪!这些模型将被广泛使用。我预计很快就会在 Ai2 的研究中使用它们。
更大的图景
在许多方面,开源 AI 模型似乎是中国公司在美国获得市场份额的最有效方式。这些模型只是巨大的数字列表,永远无法将数据发送到中国,但它们仍然传达了极高的商业价值,而不会打开对中国公司发送任何数据的担忧兔子洞。我们将继续听到这方面的讨论,尤其是 DeepSeek 的 R2 被大肆宣传并传闻即将推出(即使我不相信这些传闻)。
这些开源的中国公司正在对美国 AI 生态系统施加软实力的巨大影响。我们都可以从技术上受益。
为了好玩,我留给您 Qwen 接管 LocalLlama subreddit 的场景。目前,所有类型的模型的竞争水平都非常高。目前,默认是 Qwen。这是他们第一次彻底取代 Llama。
我们可能明天会在 LlamaCon 上听到 Meta 关于 Llama 4 推理模型的更多信息。如果模型得分质量相似而没有大量文档,我不需要再写一遍并重复自己。最大的区别是 Qwen 3 有小模型与之配套。也许我们也会从 Meta 那里得到这个,但这不是预测者所预测的。