放弃 RAG:Karpathy 的 LLM 知识库架构深度拆解与范式转移
在当前的人工智能应用领域,检索增强生成(Retrieval-Augmented Generation, RAG)几乎成为了构建企业级和个人知识库的行业标准。从简单的 PDF 问答工具到复杂的企业内部知识管理系统,其核心逻辑均依赖于将文档切片、向量化存储,并在用户提问时通过相似度检索召回相关片段供大语言模型(LLM)进行总结。然而,前特斯拉 AI 总监、OpenAI 创始成员 Andrej Karpathy 近期分享的个人知识库构建方法,对这一主流范式提出了根本性的挑战。


在当前的人工智能应用领域,检索增强生成(Retrieval-Augmented Generation, RAG)几乎成为了构建企业级和个人知识库的行业标准。从简单的 PDF 问答工具到复杂的企业内部知识管理系统,其核心逻辑均依赖于将文档切片、向量化存储,并在用户提问时通过相似度检索召回相关片段供大语言模型(LLM)进行总结。然而,前特斯拉 AI 总监、OpenAI 创始成员 Andrej Karpathy 近期分享的个人知识库构建方法,对这一主流范式提出了根本性的挑战。
Karpathy 提出了一种基于 LLM 的持久化 Wiki 架构,彻底摒弃了传统的 RAG 模式。本文将深度拆解这一架构的核心逻辑、技术实现路径及其对知识管理领域的深远影响,探讨为何“知识编译”将取代“临时检索”成为下一代知识库的终极形态。
传统 RAG 架构的系统性缺陷
要理解 Karpathy 方案的颠覆性,首先需要剖析传统 RAG 架构在处理复杂知识管理时所暴露出的系统性缺陷。尽管 RAG 能够有效缓解大模型的幻觉问题并提供外部知识补充,但其在知识的长期积累与深度整合方面存在不可逾越的瓶颈。
在典型的 RAG 系统中,知识的生命周期是高度碎片化和临时性的。当用户提出一个需要跨越多个文档、综合多重维度的复杂问题时,系统依赖于向量检索算法召回相关文本块。然而,这种召回机制本质上是基于语义相似度的模式匹配,而非真正的逻辑推理。大模型在接收到这些零散的文本块后,必须在有限的上下文窗口内“重新发现”并拼凑出答案。
这种模式的致命弱点在于知识缺乏复利效应。无论系统运行多久、处理过多少次查询,底层的知识库依然是一堆静态的、互不关联的文件切片。系统没有记忆,无法在多次查询中建立概念之间的深层链接,也无法自动识别并调和不同文档中的矛盾信息。每一次查询都是一次从零开始的计算,知识的价值在查询结束后即刻消散,未能沉淀为系统内部的结构化资产。
范式转移:从临时检索到持久化 Wiki
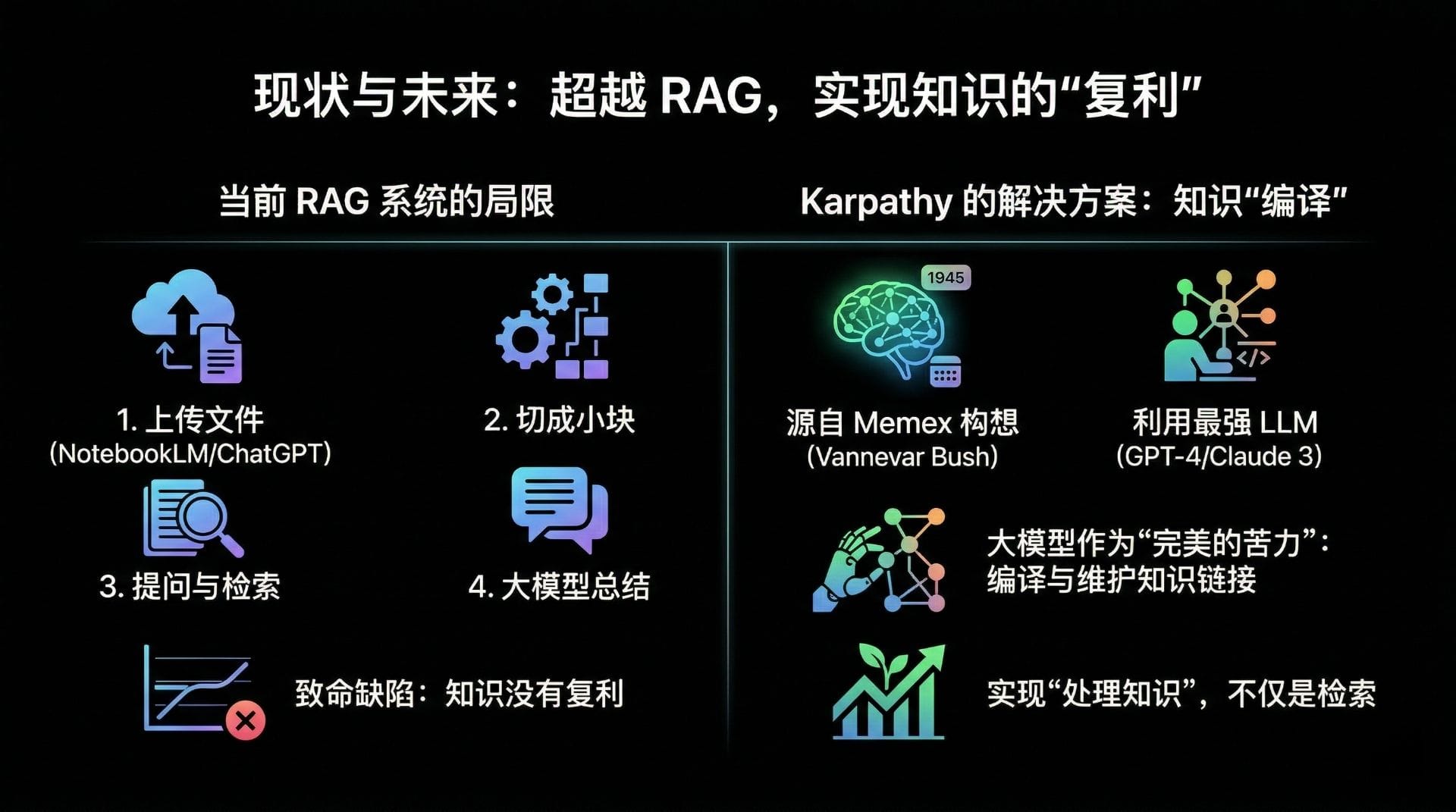
面对 RAG 的局限性,Karpathy 提出了一种回归本质但技术实现极其前沿的解决方案:利用 LLM 构建并维护一个持久化的、结构化的 Wiki 系统。这一构想在精神上呼应了 1945 年 Vannevar Bush 提出的 Memex 概念,但在技术手段上,通过引入 LLM 解决了当年无法克服的“知识链接维护”难题。
知识的“编译”而非“存储”

在 Karpathy 的架构中,知识的摄入过程不再是简单的文本切片和向量化存储,而是一次深度的“编译”(Compilation)。当一篇新的文献或数据被引入系统时,LLM 充当了编译器的角色。它不仅阅读并理解该文献的内容,更重要的是,它负责将提取出的关键信息、核心概念和实体数据,结构化地整合到现有的 Wiki 网络中。
这个过程包括更新现有的实体页面、重写相关主题的摘要、建立新的交叉引用链接,甚至在发现新数据与旧观点存在冲突时,显式地在 Wiki 页面中标记出这些矛盾。通过这种方式,知识在进入系统的那一刻就被“编译”成了结构化的网络节点。后续的查询不再需要临时拼凑信息,因为交叉引用和逻辑整合已经在编译阶段完成。每一次新知识的注入,都在实质性地丰富和强化整个 Wiki 的知识图谱,实现了真正的知识复利。
架构深度拆解:优雅的三层分离设计
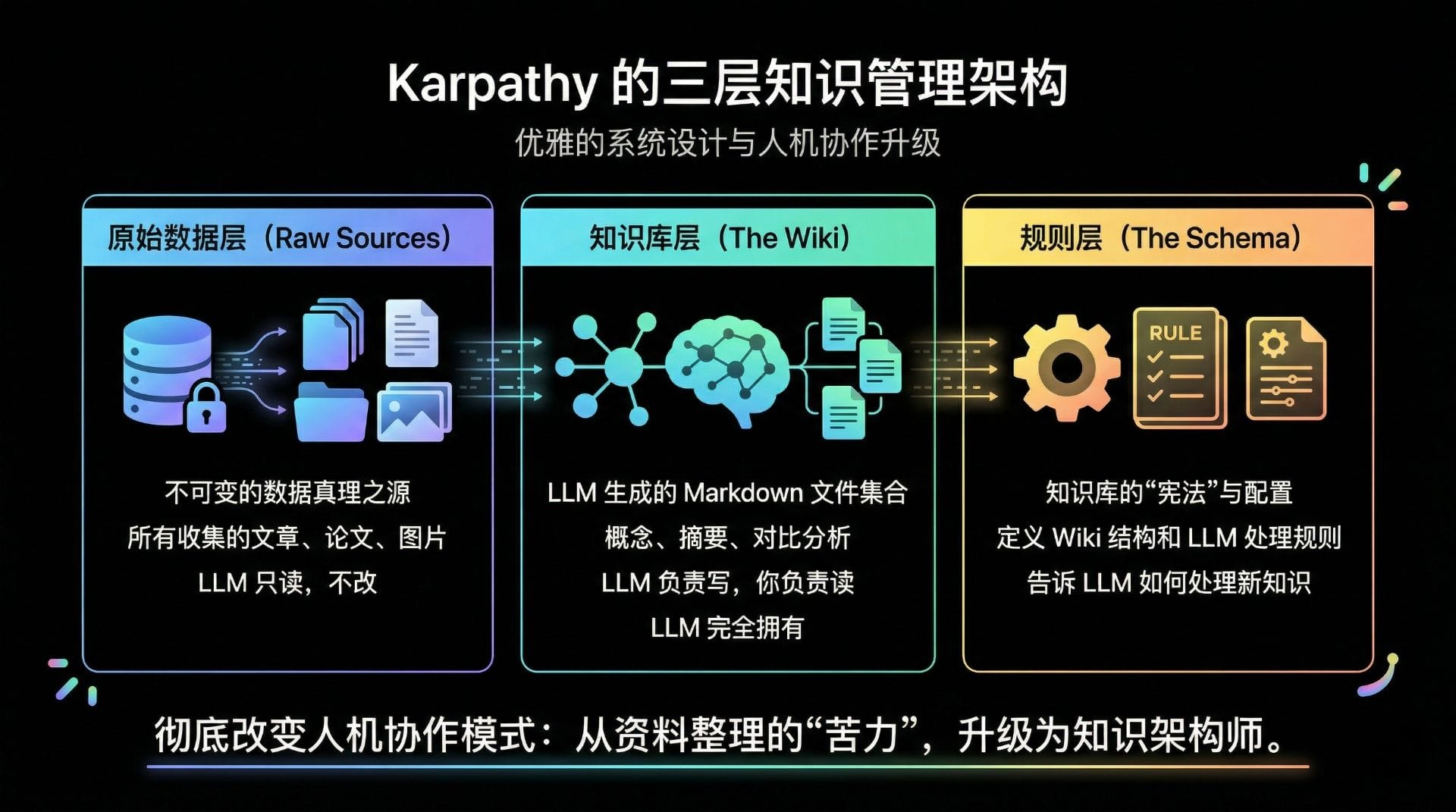
Karpathy 的 LLM 知识库之所以能够高效运转,得益于其极其严谨且优雅的三层架构设计。这种设计在软件工程中非常常见,但在知识管理领域的应用却展现出了惊人的威力,彻底厘清了人机协作的边界。
第一层:Raw Sources(原始数据层)
这是系统的基石,类似于软件工程中的源代码目录(src/)。该层存储了所有未经处理的原始文献、网页剪藏、PDF 论文和多媒体资料。在架构规范中,这一层被严格定义为不可变(Immutable)且只读(Read-only)。LLM 仅拥有读取权限,绝对禁止对原始数据进行任何修改。这种设计确保了“真理之源”的纯净性,无论上层的编译产物出现何种偏差,系统始终可以追溯到最原始、最真实的数据状态。
第二层:The Wiki(编译产物层)
这是系统的核心运行环境,类似于软件工程中的构建输出目录(build/)。该层完全由 Markdown 格式的文件组成,包含了结构化的摘要、概念定义、实体关系和对比分析。在这一层,LLM 拥有完全的读写权限(Full Ownership)。它负责创建新页面、维护双向链接、更新内容并确保全局的一致性。人类用户在这一层通常只进行阅读和查询,而将繁重的维护工作(即“记账”)完全交由 LLM 处理。
第三层:The Schema(规则配置层)
这是系统的控制中枢,定义了 Wiki 的数据结构、页面模板、链接规范以及 LLM 处理新信息的行为准则。通过调整 Schema,人类用户可以精确控制知识库的演化方向和组织形态。
这种三层分离架构彻底改变了知识管理的范式。人类从繁琐的资料整理和链接维护中解放出来,转型为知识架构师,专注于挑选高质量的信息源和制定 Schema 规则;而 LLM 则发挥其不知疲倦、擅长处理海量文本的优势,承担起知识库“记账员”和“维护者”的角色。

为何轻量级索引优于复杂 RAG?

在当前的行业语境下,优化知识库的常规思路往往是引入更先进的 Embedding 模型、部署更强大的向量数据库,或是设计更复杂的 Rerank(重排)算法。然而,Karpathy 的实践提供了一个极具冲击力的反直觉结论:在一定规模下,轻量级的文本索引远比复杂的 RAG 基础设施更有效。
知识的本质并非信息的物理堆砌,而是信息节点之间的逻辑连接。Karpathy 的个人 Wiki 在积累了约 100 篇文章、近 40 万字的数据量时,完全没有依赖任何向量数据库。系统仅通过维护几个全局的 Markdown 索引文件(如 All-Sources.md 和 All-Concepts.md),配合 LLM 自动生成的结构化摘要,就能够精准、高效地回答极其复杂的问题。
这种“大道至简”的实现方式揭示了一个深刻的道理:当知识已经被 LLM 深度编译并建立了高质量的内部链接后,检索的难度会大幅降低。复杂的 RAG 架构往往是在试图用算法弥补底层知识结构化的缺失。与其在检索端投入巨大成本,不如在知识摄入端通过 LLM 做好“编译”工作。先跑通基于轻量级索引的最小闭环,待知识规模真正突破物理瓶颈时,再考虑引入向量检索作为辅助手段,这才是更符合工程逻辑的演进路径。
落地实践:基于 LLM 的知识编译工作流
要将 Karpathy 的理论转化为实际的生产力工具,需要建立一套标准化的“知识编译”工作流。这套工作流涵盖了知识生命周期的四个核心环节,形成了一个自我强化的闭环系统。
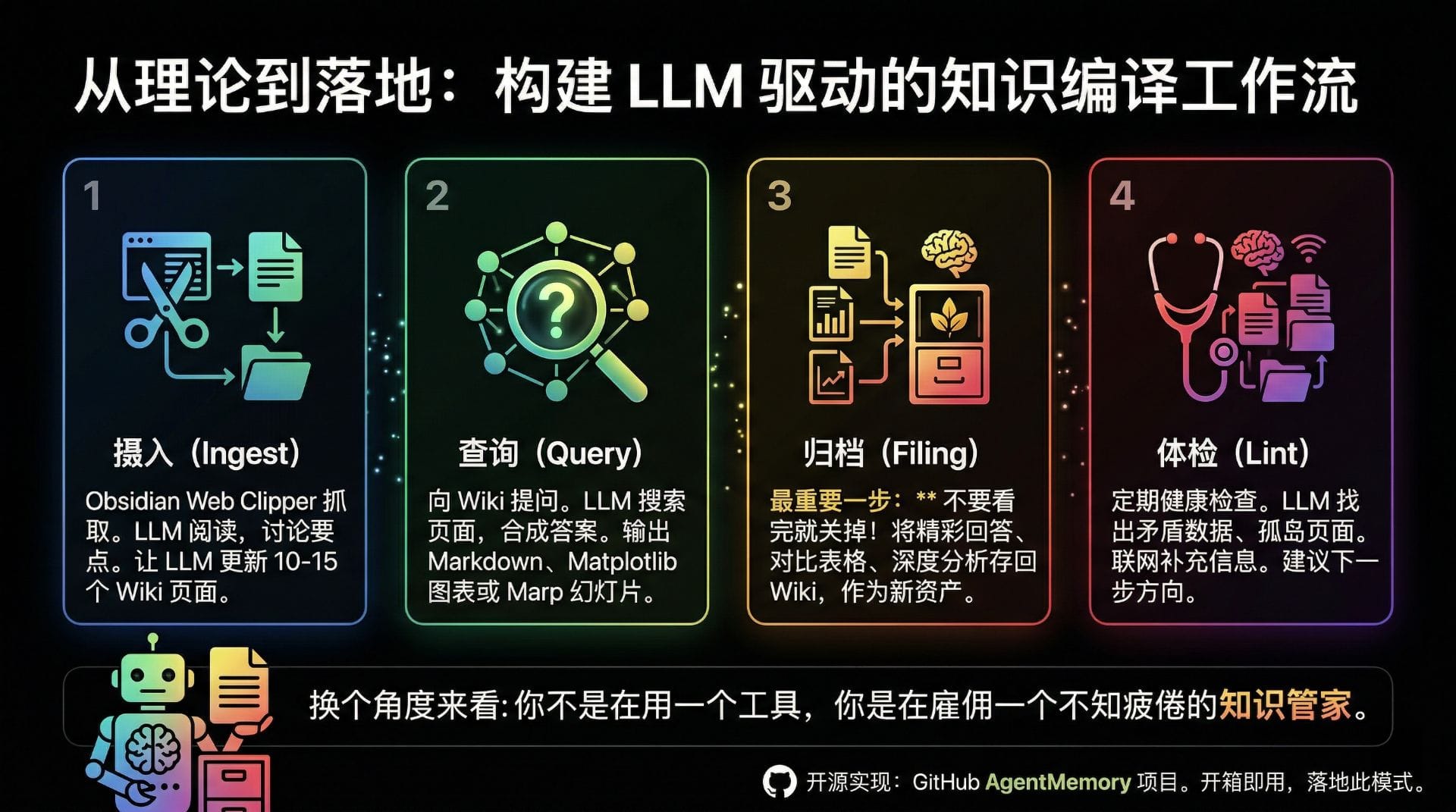
1. 摄入(Ingest):知识的结构化捕获
摄入环节是知识编译的起点。用户通过工具(如 Web Clipper 或自动化脚本)将高质量的原始资料捕获至 Raw Sources 层。随后,触发 LLM 的编译进程。LLM 会深度阅读原始资料,提取核心论点、关键数据和新概念,并根据 Schema 规则,自动生成结构化摘要,同时更新或创建 10 到 15 个相关的 Wiki 页面。这一过程确保了新知识在进入系统的瞬间,即被无缝编织入现有的知识网络中。
2. 查询(Query):交互式的知识图谱
在查询环节,Wiki 不再是一个静态的文档库,而是一个可交互的知识图谱。当用户提出问题时,LLM 会基于全局索引和相关页面的结构化内容,进行逻辑推理和信息合成。由于知识已经过预编译,LLM 能够输出高度准确、逻辑严密的答案,并可根据需求直接生成 Markdown 报告、数据可视化图表(如 Matplotlib 脚本)或演示文稿结构。
3. 归档(Filing):对话即资产
这是该工作流中最具创新性的一环。在传统的 AI 交互中,对话结束后,产生的高质量推理和分析往往随之消散。而在知识编译工作流中,LLM 生成的深度回答、对比分析矩阵和复杂问题的推理过程,会被显式地保存为新的 Markdown 文件,归档至 Wiki 中。这意味着,用户的每一次高质量提问,都在为知识库创造新的资产。系统通过不断吸收这些“运行时输出”,实现了知识库的自我生长。
4. 体检(Lint):自动化技术债修复
如同软件工程需要持续的重构和测试,知识库也存在“技术债”——例如定义冲突的概念、失效的链接或缺乏支撑的孤岛页面。在体检环节,系统定期(如每周)调度 LLM 对整个 Wiki 层进行全局扫描。LLM 会自动识别并修复一致性错误,补充缺失的链接,甚至通过联网搜索补全关键信息。这种自动化的健康检查机制,确保了知识库在长期演进中始终保持高可用性和高可信度。
行业展望:知识管理的“GitHub 时刻”
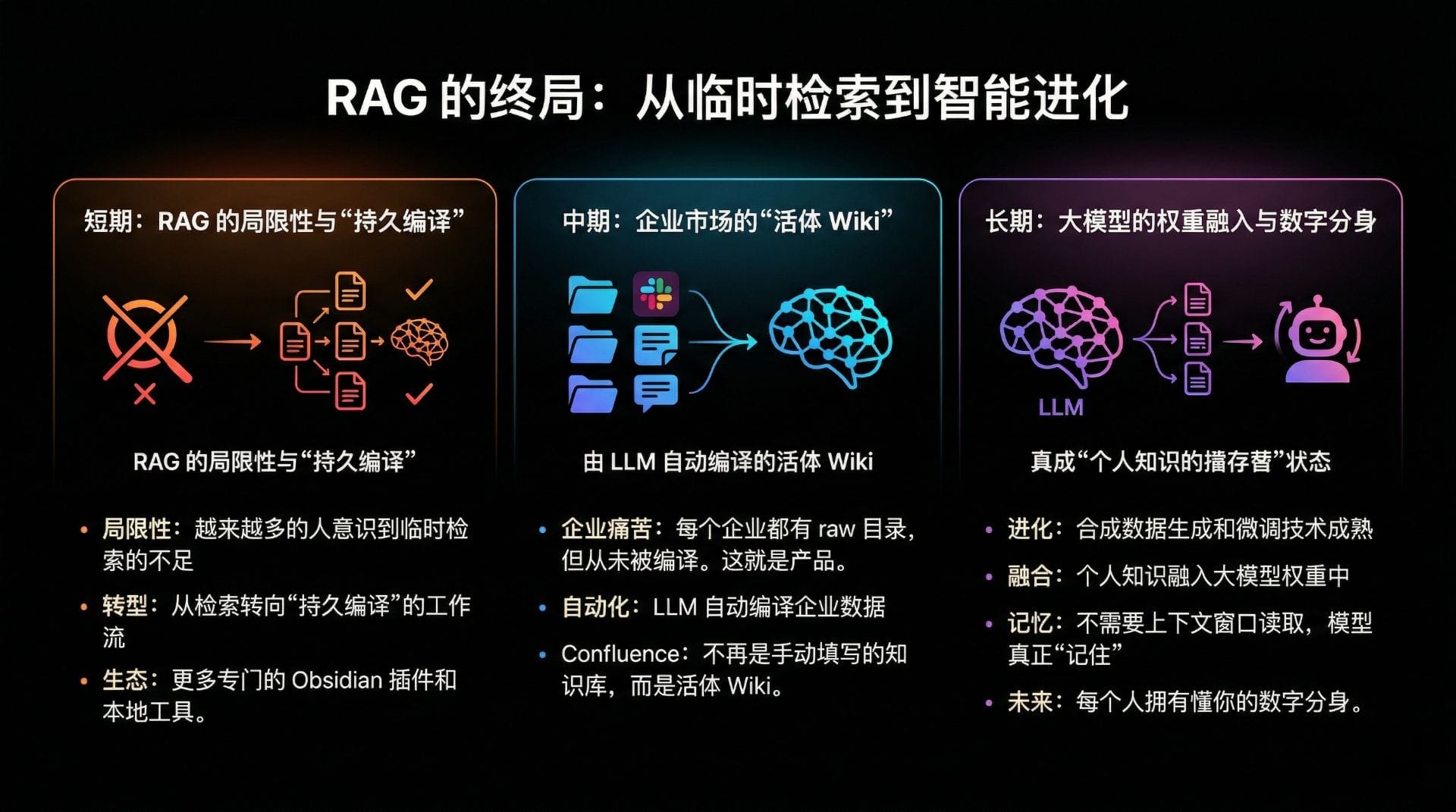
Karpathy 的 LLM 知识库架构不仅是对个人知识管理工具的升级,更是对整个知识管理行业范式的重塑。我们正处于知识管理的“GitHub 时刻”。
在短期内,随着开源社区(如 GitHub 上的 AgentMemory 项目)对该架构的复现和优化,我们将看到越来越多基于 Obsidian、Notion 等本地工具的“知识编译”插件涌现。用户将逐渐从“临时检索”的思维定势中觉醒,转向追求“持久编译”的知识复利。
在中期,这一架构将对企业级知识管理市场产生深远影响。正如 Karpathy 所言:“每个企业都有一个 raw 目录,但从来没有人编译过它。这就是产品。”未来的企业知识库将不再依赖员工手动维护的静态 Wiki(如 Confluence),而是演变为由 LLM 自动从内部通讯(Slack)、会议记录、研发文档和客户反馈中实时编译、持续更新的“活体知识图谱”。
从长期来看,这种知识编译的模式甚至可能改变大语言模型自身的演进路径。随着合成数据生成技术和高效微调(Fine-tuning)算法的成熟,高度结构化、经过深度编译的个人或企业 Wiki,将成为最优质的训练语料。最终,这些知识库可能会直接融入大模型的权重之中,使得模型不再需要通过外部检索来获取上下文,而是真正“记住”并内化这些专属知识,从而诞生出真正意义上的个性化数字分身。
结语
传统 RAG 架构在解决大模型信息滞后问题上功不可没,但其在知识积累与深度整合上的结构性缺陷已日益凸显。Karpathy 提出的基于 LLM 的持久化 Wiki 架构,通过引入“知识编译”的概念和优雅的三层分离设计,为我们指明了下一代知识管理系统的演进方向。
在这个新范式下,人类的职责回归到知识的策展与规则的制定,而 LLM 则承担起繁重的知识链接与维护工作。知识库的未来,不再是追求更精准的临时检索,而是致力于构建能够自我生长、持久演进的编译系统。 掌握并应用这一架构,将是在 AI 时代获取认知红利的关键所在。
附件
https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f