DeepSeek 时刻!Google TurboQuant,算力霸权被彻底打破
Google 刚发布的 TurboQuant 论文在 X(原 Twitter)上引发了超过 1000 万次阅读,整个 AI 工程圈都在讨论这项技术。但网上很多解读要么停留在表面,要么误解了它真正提速的底层逻辑。本文将剥离复杂的公式,用最直白的语言,把这项技术的本质讲透——小学水平也能看懂。


Google 刚发布的 TurboQuant 论文在 X(原 Twitter)上引发了超过 1000 万次阅读,整个 AI 工程圈都在讨论这项技术。但网上很多解读要么停留在表面,要么误解了它真正提速的底层逻辑。本文将剥离复杂的公式,用最直白的语言,把这项技术的本质讲透——小学水平也能看懂。

一、从 KVCache 说起:大模型的"记忆缓存"
在聊 TurboQuant 之前,我们需要先理清一个核心概念:KVCache。
大模型生成文字,是典型的"自回归"过程——字是一个一个蹦出来的。为了避免每生成一个新字,都要把前面所有的对话重新计算一遍,科学家引入了 KVCache。你可以把它理解为大模型的**"记忆缓存"**,里面存储着之前所有上下文的特征状态。

但这带来了一个致命问题:随着对话越来越长,这个"记忆缓存"会变得极其庞大,最终拖慢整个推理速度。
我们不妨把 KVCache 想象成一个三维的数据立方体,它有长、高、宽三个维度:
| 维度 | 含义 | 问题 |
|---|---|---|
| 长(上下文长度) | 对话越长,数据越多 | 无限增长,撑爆显存 |
| 高(特征维度) | 模型对每个词的特征表达大小 | 模型越大,越占空间 |
| 宽(数据精度) | 保留几位小数(如 FP16/BF16) | 精度越高,体积越大 |

为了防止 KVCache 把显存撑爆,学术界之前的主要精力都集中在压缩"长"和"高"这两个维度上。
二、压缩"长":滑动窗口注意力
滑动窗口注意力(Sliding Window Attention) 是目前最常用的压缩"长"的方法。简单来说,就是限制模型只保留最近一段对话的 KVCache(比如最后 1024 个 Token),更早的内容直接丢弃。
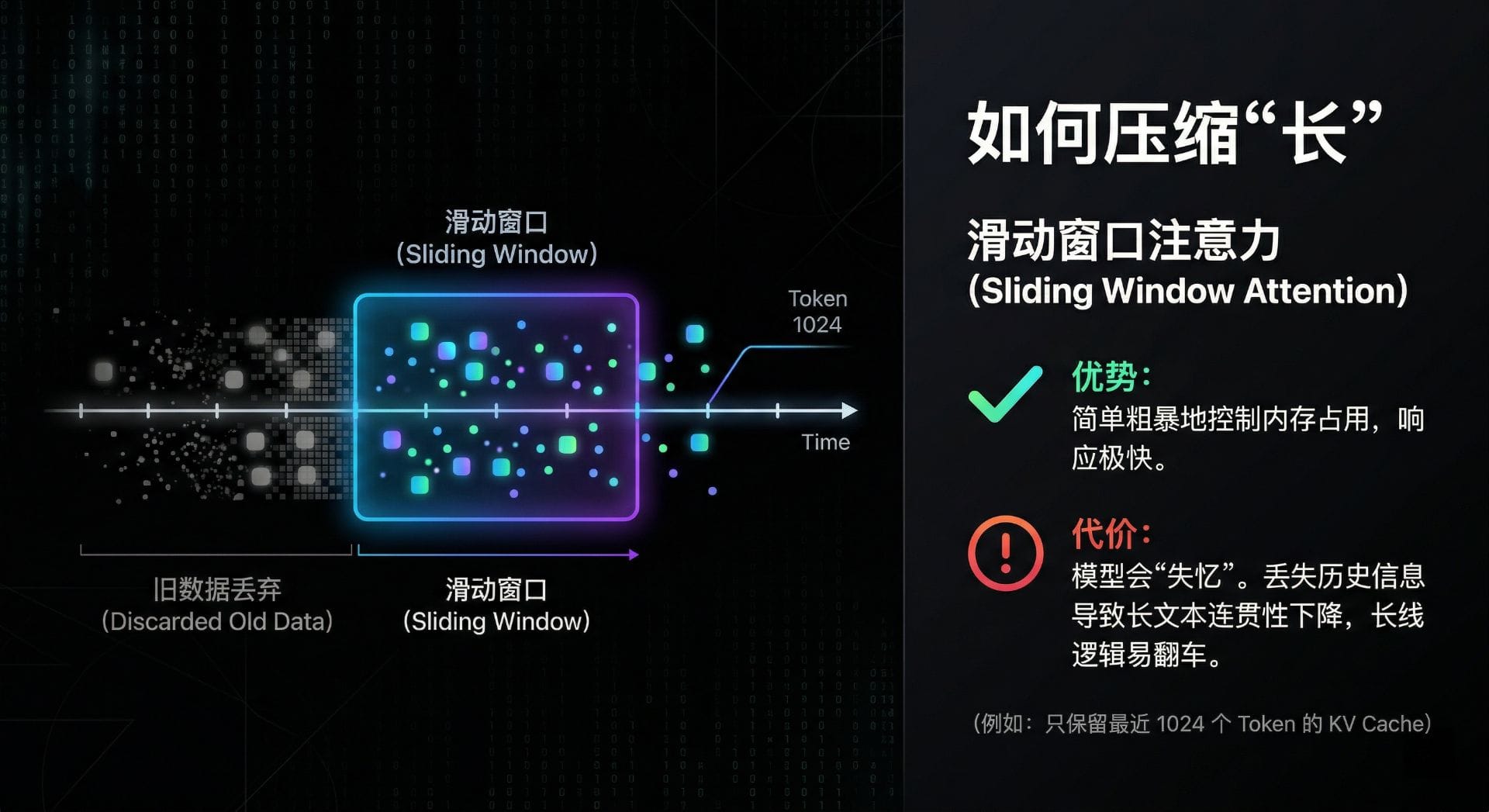
这个方法有明显的优缺点:
- 优势:简单粗暴地控制了内存占用,响应极快
- 代价:模型会"失忆"。丢弃历史信息会导致长文本连贯性下降,处理长线逻辑时容易翻车
三、压缩"高":线性注意力
线性注意力(Linear Attention) 则是压缩"高"的代表方案。它不丢弃历史,而是通过算法,把所有过去的信息压缩成一个固定大小的"隐状态向量"。不管你聊了多久,KVCache 的"高度"恒定不变。

同样有利有弊:
- 优势:突破了长度限制,保留了全局上下文
- 代价:这种压缩是"有损"的,会丢失大量细节;算法实现相对复杂,在某些具体任务上的表现并不均衡
这两种方法,都在努力控制 KVCache 的体积。但过去,很少有人敢去动那个最敏感的维度——"宽",也就是数据精度。
四、TurboQuant 的核心突破:3-bit 无损压缩
把原本 16 位(16-bit)的浮点数精度强行砍掉?在过去,把精度降到 3-bit 几乎等同于让模型变成"人工智障",信息丢失率会高到无法接受。

但这正是 Google TurboQuant 这篇论文的核心突破:它实现了近乎无损的 3-bit KVCache 压缩。他们是如何做到的?论文中提出了两个核心算法的组合拳:
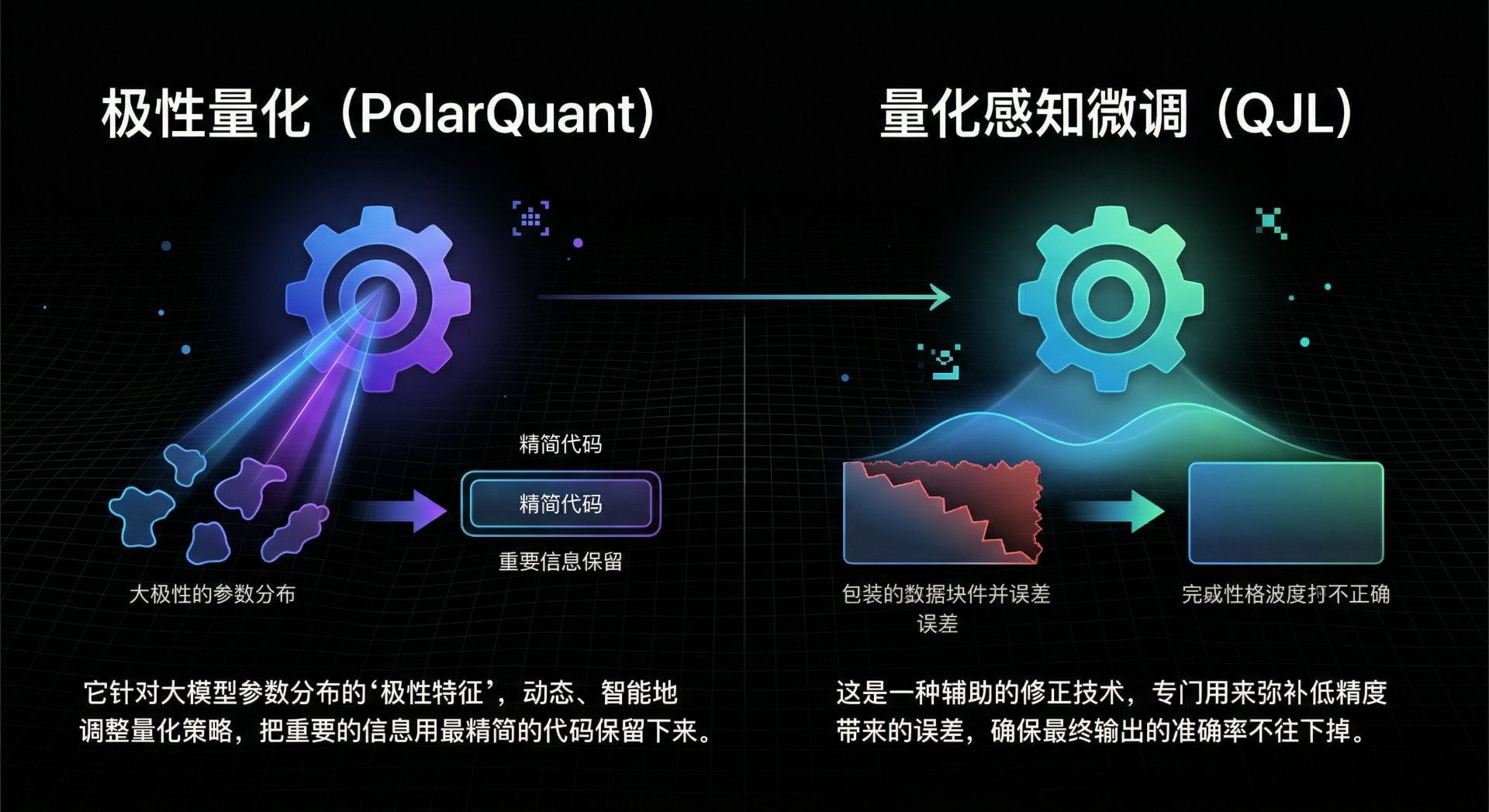
1. PolarQuant(极性量化)
它不再使用一刀切的压缩方式,而是针对大模型参数分布的"极性特征",动态、智能地调整量化策略,把重要的信息用最精简的代码保留下来。
2. QJL(量化感知微调)
这是一种辅助的修正技术,专门用来弥补低精度带来的误差,确保最终输出的准确率不往下掉。
这两套组合拳打完,效果如何?

KVCache 的数据体积直接缩小了 4 到 5 倍,而模型的输出质量几乎没有肉眼可见的衰减。
要知道,今天很多普通大模型的 KVCache 还在用 16-bit(FP16/BF16)跑!从 16-bit 到 3-bit,这是一次质的飞跃。
五、破除迷思:速度到底是怎么提上来的?
听到这里,重点来了。很多人误以为,数据变成 3-bit,是因为显卡计算这些数字变得更快了。

这是一个极大的误区!
事实是,现代 GPU(比如 H100)里的 Tensor Core,底层硬件支持的最小计算精度通常是 INT8 或者 FP8。这意味着,哪怕你把数据压缩成了 3-bit,在进入计算核心之前,它依然得在片上缓存里被重新扩展成 8-bit 才能进行运算。
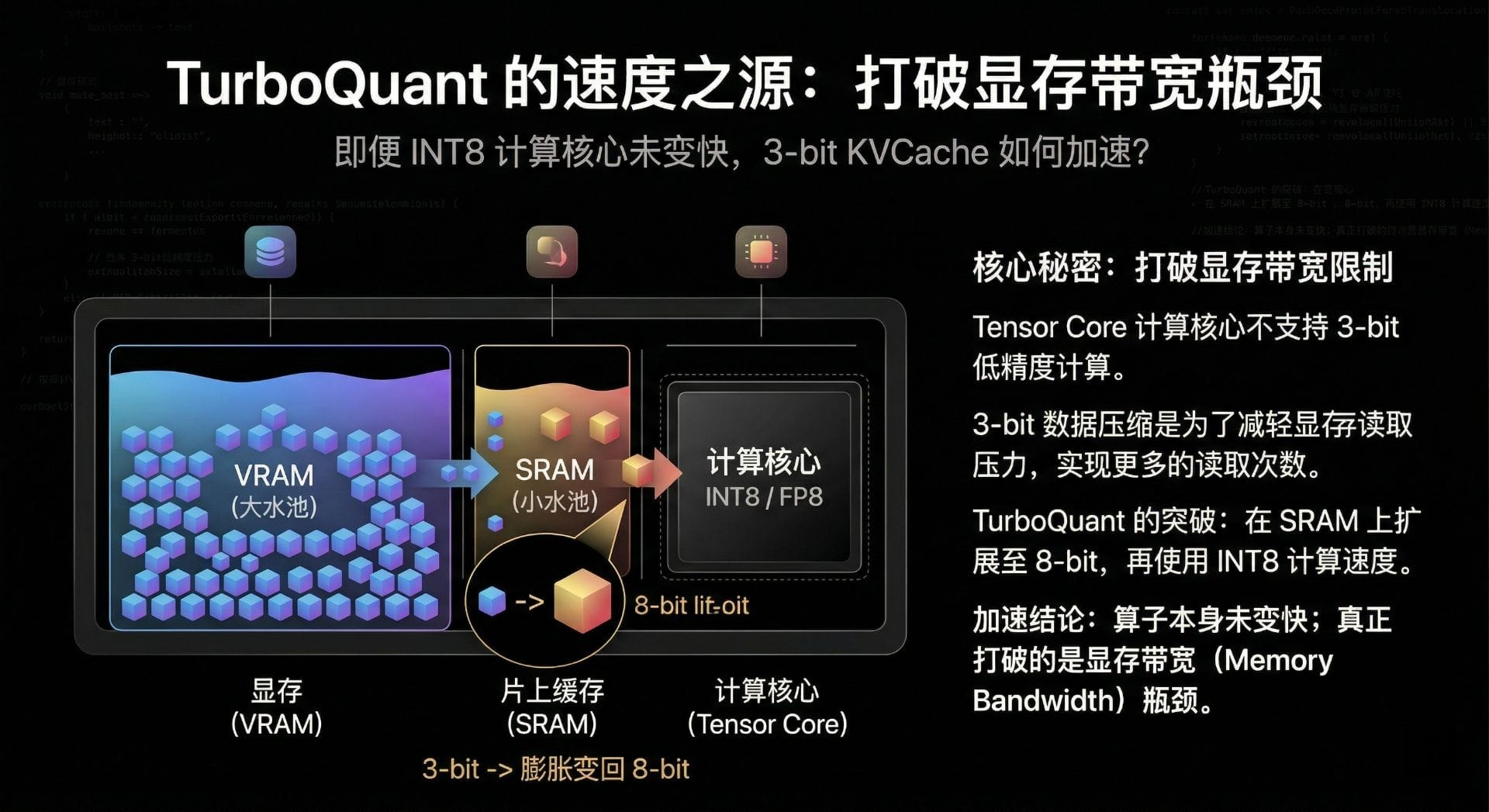
既然算子没有变快,那速度是从哪来的?答案是:显存带宽(Memory Bandwidth)。
六、真正的瓶颈:显存带宽,而非 GPU 算力
对于大模型推理来说,最大的瓶颈根本不是 GPU 的算力(Compute-bound),而是数据的读写速度(Memory-bound)。
用一个形象的比喻来理解:
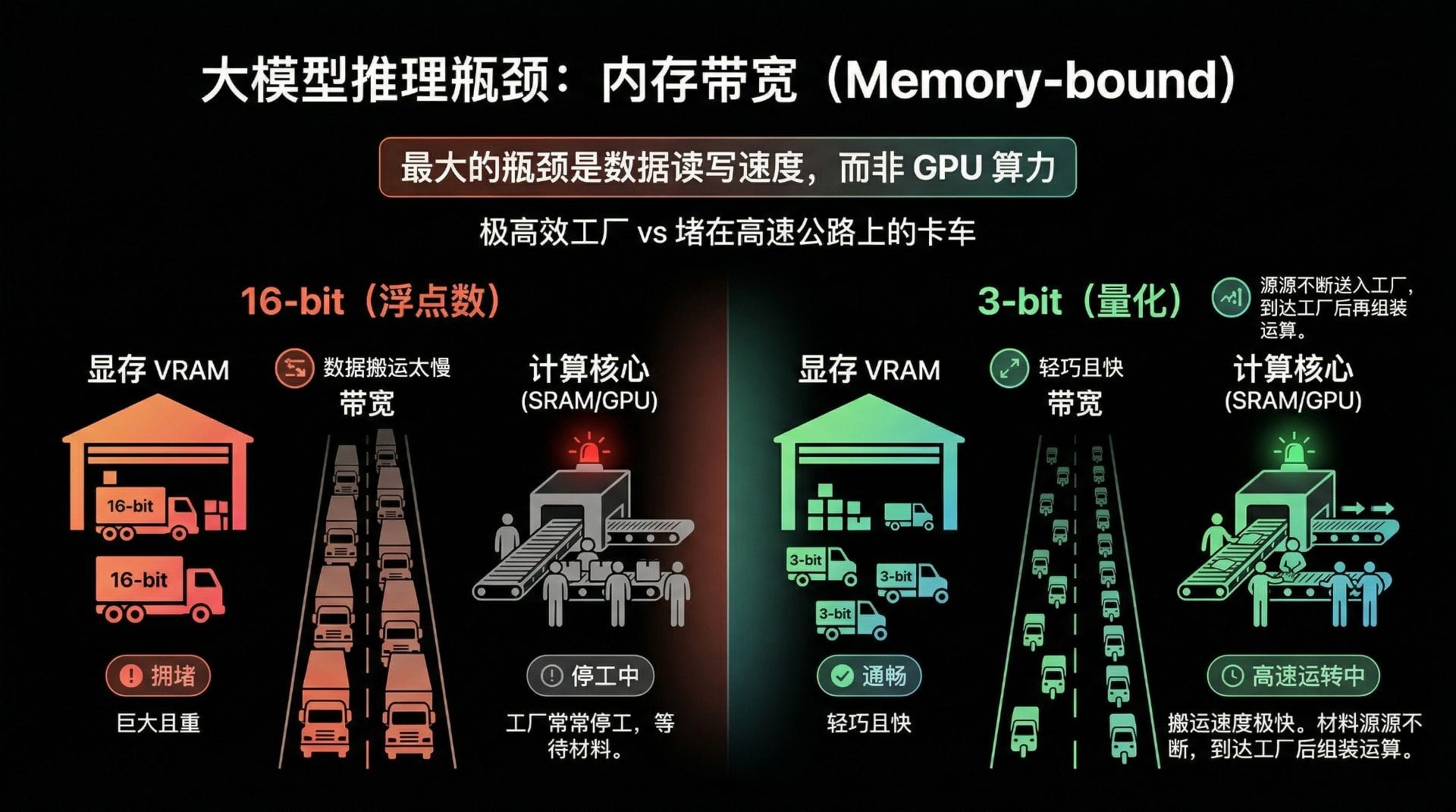
想象一个极其高效的加工厂(GPU 计算核心),流水线转得飞快,但运送原材料的卡车却堵在了高速公路上。显存(VRAM)和 GPU 高速缓存(SRAM)之间的数据搬运,就是那条拥挤的高速公路。
- 16-bit 的情况:数据量庞大,就像一辆辆重型卡车,严重堵塞带宽公路,工厂常常停工等材料
- 3-bit 的情况:数据量缩小 4-5 倍,就像换成了轻巧的快递小车,公路瞬间通畅,材料源源不断送入工厂
TurboQuant 的 3-bit 压缩,本质上是把原本需要装载 5 辆卡车的数据,压缩到了 1 辆卡车里。虽然到了工厂还是要拆包还原,但数据在显存和 GPU 之间传输的时间被大幅削减了。
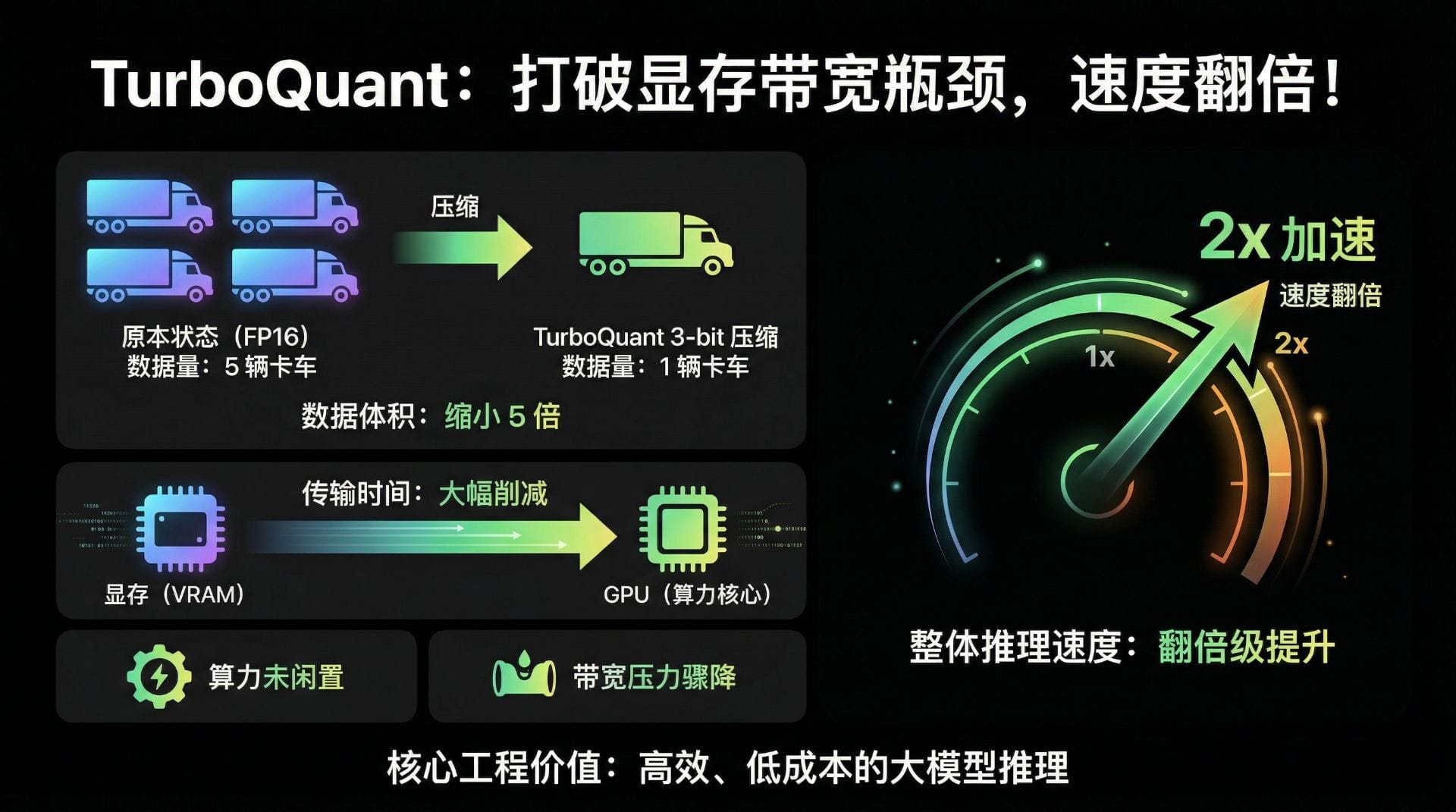
算力没有闲置,带宽压力骤降,整体的推理速度自然就迎来了翻倍级的提升。这就是 TurboQuant 最核心的工程价值。
七、行业影响:打破隐形天花板,重塑 AI 生态
理解了显存带宽这个"隐形天花板",你就能明白 TurboQuant 对整个 AI 行业的深远意义。
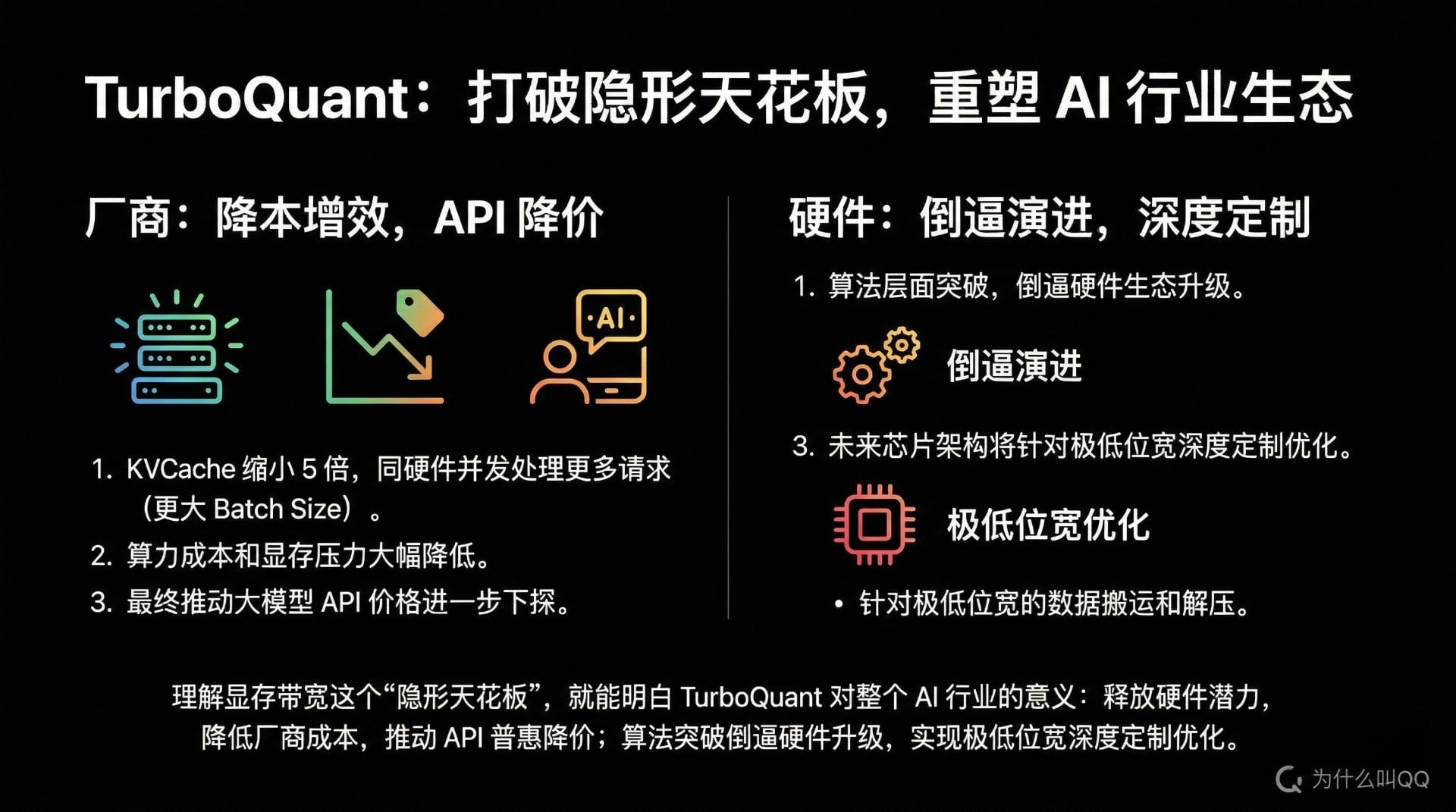
对云服务厂商:降本增效,API 降价
KVCache 体积缩小 5 倍,意味着同样的硬件可以并发处理更多用户的请求(更大的 Batch Size)。算力成本和显存压力大幅降低,最终必然会推动大模型 API 价格的进一步下探。
对硬件生态:倒逼演进,深度定制
这种算法层面的突破,也会倒逼硬件生态的演进。未来的 AI 芯片架构,很可能会针对极低位宽的数据搬运和解压,做出更深度的定制优化。
对终端用户:端侧部署加速,实时智能普及
TurboQuant 不仅仅是一次简单的"降维",它为大模型在端侧的部署、以及实时智能助手的普及,扫清了一个巨大的硬件障碍。
八、总结:这次是真正的 DeepSeek 时刻
回顾整个 TurboQuant 的技术逻辑,我们可以用一张表格来梳理它的核心价值:
| 维度 | 传统方案 | TurboQuant |
|---|---|---|
| KVCache 精度 | 16-bit(FP16/BF16) | 3-bit(近乎无损) |
| 数据体积 | 基准 1x | 缩小 4-5 倍 |
| 提速原理 | — | 打破显存带宽瓶颈 |
| 输出质量 | 基准 | 几乎无衰减 |
| 推理速度 | 基准 1x | 翻倍级提升(约 2x) |
| 适用场景 | 标准推理 | 长上下文、高并发场景效果尤为显著 |
三句话总结 TurboQuant 的核心洞察:
- 带宽是 AI 加速的"隐形天花板" —— 不是算力不够,是数据搬运太慢
- TurboQuant 突破了数据读写瓶颈 —— 用 PolarQuant + QJL 实现了 3-bit 无损压缩
- AI 提速不靠算力,靠的是带宽! —— 这才是这篇论文最反直觉、也最重要的工程洞见
如果 TurboQuant 能进一步搭配线性注意力或滑动窗口注意力,未来模型的推理速度翻倍完全没有悬念。这不仅是一篇学术论文,更是一次真正意义上的工程范式转移。
本文基于 Google TurboQuant 论文及相关技术分析整理,如有技术细节出入欢迎指正。
作者:为什么叫QQ | 转载请注明出处