AI 如何影响程序员的技能形成:arXiv 2601.20245 深度解读
当所有人都在欢呼“自然语言即编程语言”时,Anthropic 的一篇最新实验论文,给程序员泼下了一盆冷水。 这项研究关注的不是“AI能不能帮你更快写代码”,而是一个更关键的问题:AI会不会让你交付更快,却学得更少? 实验结果很耐人寻味:效率提升并没有想象中那么夸张,但在禁用 AI 的测试里,使用 AI 的那组开发者,核心理解和调试表现明显更弱。最值得警惕的,不是代码写得快,而是你越来越少经历报错、定位、假设、验证这一整套真正训练程序员能力的过程。


概述
这篇论文研究的不是“AI 写代码能不能更快”,而是更尖锐的问题:当你在工作中学习新工具/新库时,AI 辅助会不会让你交付更快但学得更少。作者用随机对照实验让开发者在学习一个新异步库时完成任务,并用禁用 AI 的测验来检测“技能形成”。
主要结论可以浓缩为四句话:
一是,在主实验(n=52)中,AI 组完成任务时间略快但不显著(图中 p=0.391);但在知识测验上显著更差(p=0.010),测验分数大约低 17%(约两档成绩)。
二是,最“伤”的并不是语法记忆,而是调试能力:分差最大的子项出现在 debugging 题。
三是,作者用屏幕录屏做了质性分析,发现许多人为了把 AI“用对”,会投入大量对话时间:有人在 35 分钟任务里与 AI 交互累计到 11 分钟、提问到 15 次——这类成本会吞噬生产力收益(我在下文称为“交互税”)。
四是,AI 并非必然导致更差学习:论文识别出 6 种 AI 使用“人格”,其中 3 种“高认知参与”的用法(问概念/要解释/先生成再追问理解)能把测验维持在 65%–86%,而“全委托/反复 AI debug”等模式只有 24%–39%。
研究问题与方法
研究场景高度贴近“上班学新库”:作者选择了 Python 的 Trio 异步并发库,理由是它相对 asyncio 更小众、包含结构化并发等新概念,并适合做学习实验。

主实验流程可概括为:
参与者先做一个与异步无关的热身题(无 AI,用于校准 Python 熟练度与熟悉平台),随后在 35 分钟内完成 2 个 Trio 任务;任务后做一套禁用 AI 的测验(14 题、总分 27 分),再填写问卷。
实验条件是“组间随机对照”:
- AI 组:主任务阶段可用聊天式 AI 编码助手(基础模型为 的 GPT‑4o),助手能看到参与者当前代码,且在被要求时能生成完整正确解答。
- 对照组:主任务阶段无 AI。两组都被要求尽快完成,并在测验阶段禁用 AI。
测验指标刻意强调“监督 AI 必须具备的能力”:调试(debugging)、代码阅读(code reading)、概念理解(conceptual)。作者刻意不考“代码书写/语法记忆”,避免把结果变成“谁记得更多 API 拼写”。
此外,论文有多轮 pilot 来解决线上实验常见问题(例如对照组偷用 AI 的合规性问题、测验题之间相互提示造成的 local item dependence 等)。
实验条件、指标与关键结果表
下表按“实验条件—指标—结果”把论文最核心的信息压缩出来(未在论文中给出者标为“未说明”)。
| 维度 | AI 组(Treatment) | 无 AI 组(Control) | 备注 |
|---|---|---|---|
| 样本量 | 26(主实验 n=52) | 26(主实验 n=52) | 平衡性表见论文 Table 1 |
| 热身阶段(上限) | 10 分钟,无 AI | 10 分钟,无 AI | 热身题平均约 4 分钟(平台统计) |
| Trio 主任务(上限) | 35 分钟,可用聊天式 AI 助手 | 35 分钟,无 AI | 两组都可运行代码;论文记录了 Websearch 事件 |
| 测验(上限) | 25 分钟,禁用 AI | 25 分钟,禁用 AI | 14 题、27 分;覆盖 Trio 7 个核心概念 |
| 主要产出指标 | 完成时间(分钟) | 完成时间(分钟) | 图 6:p=0.391(不显著) |
| 主要学习指标 | 测验得分(% / 27 分) | 测验得分(% / 27 分) | 图 6:p=0.010;均值差 4.15/27 ≈ 17% |
| 错误数量(中位数) | 总错误 1.0(Q1–Q3:0–3) | 总错误 3.0(Q1–Q3:2–5) | Table 4;无 AI 组出现更多 Trio 相关错误 |
| 交互与过程指标 | AI 交互时长、提问数、提问类型 | 仅平台运行/搜索等 | AI 组有人提问到 15 次、交互到 11 分钟 |
论文把“AI 组内部差异”也量化成 6 种交互人格(Figure 11),这对实践非常关键:不是“用不用 AI”,而是“怎么用”。
| AI 使用人格(论文定义) | n | 平均完成时间 | 平均测验分数 | 直观含义 |
|---|---|---|---|---|
| Generation-Then-Comprehension | 2 | 24 min | 86% | 先让 AI 生成,再追问理解与核对 |
| Hybrid Code-Explanation | 3 | 24 min | 68% | “生成 + 解释”绑定在同一提问里 |
| Conceptual Inquiry | 7 | 22 min | 65% | 只问概念,错误自己解决 |
| AI Delegation | 4 | 19.5 min | 39% | 让 AI 生成后直接粘贴交卷 |
| Progressive AI Reliance | 4 | 22 min | 35% | 前面少量求助,后面逐步全委托 |
| Iterative AI Debugging | 4 | 31 min | 24% | 反复让 AI 排错/确认(5–15 次提问) |
与“交互税”直接相关的过程数据也给得很具体:论文把 AI 输入分成解释/生成/调试/能力询问/感谢 5 类,解释类提问最多(q=79),其次是代码生成(q=51);仅约 2/3 的 AI 组成员实际用过“生成代码”类提问,这解释了为什么平均生产力提升并不稳定。
交互税与“少报错”如何伤害核心推理
交互税是什么
论文没有把 interaction tax 当成正式术语,但它的质性分析指向一个非常清晰的“隐性成本”:把 AI 用到“可交付”本身就需要交互成本——你要构思提示词、补上下文、反复追问、等待结果、再核对。
在实验里,这种成本有可量化的上限:
有人在 35 分钟的任务里累计与 AI 交互到 11 分钟(约占 30%),提问到 15 次;论文指出,正是这批“高交互时长”参与者,使得 AI 组整体并未显著更快(图 12 的解释)。
把它说得更工程化一点:当任务需要新知识时,AI 不只是“生成器”,它会变成一个你必须管理的“外部系统”。你付出的时间从“写代码”转移到“与 AI 协商正确的代码”。论文也观察到:使用 AI 会显著减少“实际在敲代码的 active time”,而无 AI 组通常 active time 更高、测验分数也更高。
为什么“少报错/少看报错”会削弱推理链
论文给了一个非常强的因果叙事:无 AI 组学习更好,一个重要渠道来自“遇到错误→独立解决错误”的过程。
数据上,“少报错”是明显存在的:无 AI 组的错误中位数更高(总错误 3 vs 1),并且更常出现与 Trio 关键概念强关联的错误类型(例如 coroutine never awaited、把 coroutine 传给需要 async function 导致的 TypeError 等)。作者强调,这类错误会强迫你理解 await、nursery、错误传播等关键机制,而这些内容正被测验覆盖。
这就解释了用户问题里“为什么减少错误信息会伤害程序员核心推理”:
编译器/运行时的 error message 不是噪音,而是一个“对你心智模型的单元测试”。当你必须自己读栈、定位、提出假设、做最小修改验证,你被迫走完整的推理闭环。AI 帮你把坑铺平、或直接给出“修好的版本”,你就少了这条闭环的反复训练——而论文发现分差最大的子项恰恰是 debugging。
一个容易被忽略的细节是:“多打字/少粘贴”本身并不保证学得更多。论文对比了“直接粘贴 AI 代码”和“手动抄写 AI 代码”的人:前者确实更快;但在测验分数上差异并不明显。作者据此推断:决定学习的是认知努力,而不是手部劳动时间。
批判性评估与可复现性
这篇工作在“因果证据”层面相对扎实:它是组间随机对照实验,测验在两组都禁用 AI,且测验题设计考虑了题目相关性与 local item dependence(基于 item response theory 的多轮测试与修订)。
论文还补充了录屏标注的质性分析,使得“为什么没显著变快、为什么学得更差”不只是相关性推测。
但它也有几类需要认真对待的局限与可能混杂因素(其中不少作者在 Future Work 里已主动点出):
- 任务与工具形态的外推:实验基于单一新库(Trio)和聊天式助手。作者认为聊天式可能是“认知外包的下界”,因为更自动化的 agentic/autocomplete 工具对人的要求更低,潜在退化可能更强——这需要专门验证。
- 时间尺度:技能形成通常是月/年尺度,而本文测的是约 1 小时内的“即时掌握度”(测验紧随任务)。这更像短期记忆与初步心智模型的评估;长期是否会追上、是否会出现“后来补课”效应,文中未能回答。
- 激励结构:参与者被强调“尽快完成”、并以固定报酬参与;这可能让一些人用更激进的“全委托”策略,放弃深度理解,进而放大负面学习效应。论文也记录到参与者自己提到“赶时间导致没建立心智模型”的反馈。
- 提示词能力未直接测量:作者仅收集了自报的 AI 熟悉度,没有把“提示词熟练度”作为独立变量测量;而这可能决定你是否能进入高分的“认知参与型”模式。
- 替代解释空间:结果也可以被解释为“AI 让你更少遇到错误,所以更少练到调试”,这并不等价于“AI 让你无法理解”,而是“默认工作流剥夺了练习机会”。这恰恰意味着:如果我们把 AI 产品设计成强制解释/强制自检,学习损失未必不可逆。
可复现性方面,这篇论文做得相对“研究友好”:
作者公开了任务与标注数据:包括任务说明、起始代码、参考解、以及标注过的参与者交互转写,托管在GitHub 上,论文也说明 51/52 人上传了录屏,并对其中主任务录屏进行了事件级标注(含 Websearch、AI Query、Error 等事件)详见文末的链接。
给程序员的实践要点:把 AI 当导师
论文最重要的启发并不是“禁用 AI”,而是:如果你在学新东西(新库/新框架/新语言特性),应当刻意把自己推向论文里的高分模式(Conceptual Inquiry、Hybrid Code-Explanation、Generation-Then-Comprehension),避免低分模式(代写、反复让 AI debug)。
下面给一套“把 AI 当导师”的工作流,目标是保住你的心智模型构建与调试推理链(即最稀缺的监督能力)。
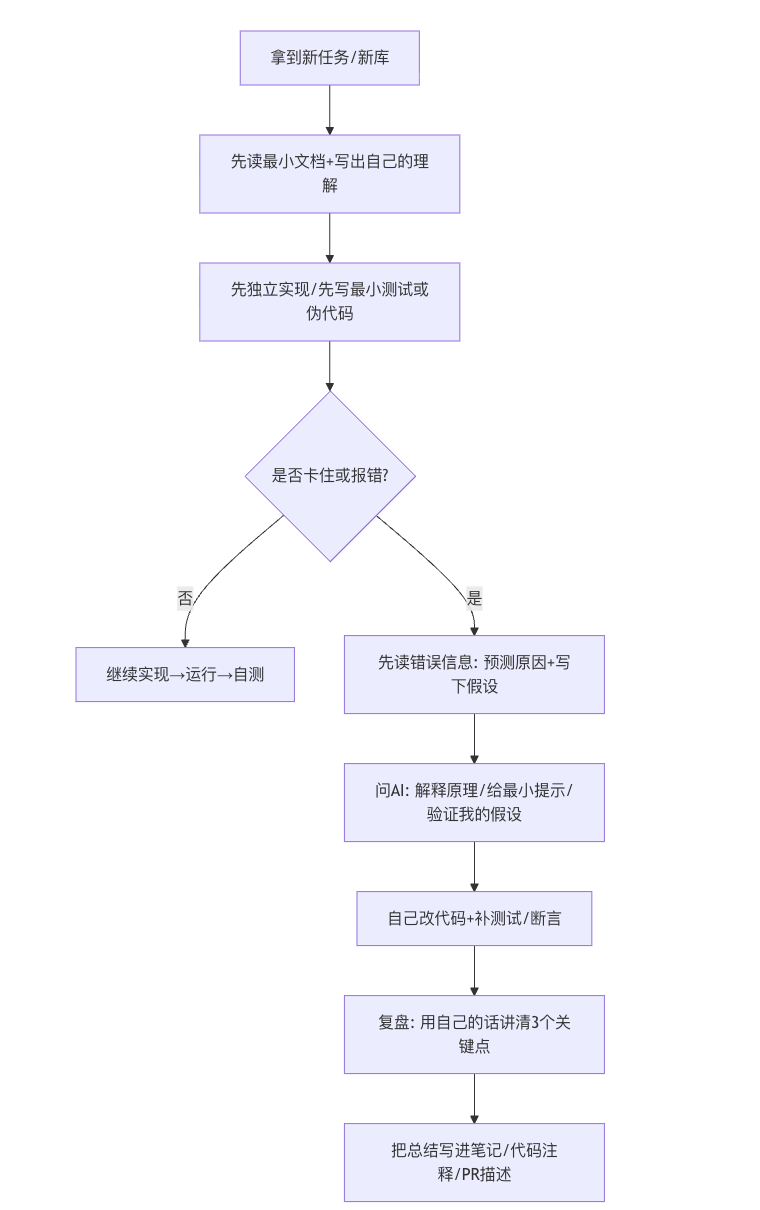
可以直接复制的“保技能提示词模板”(把输出从“答案”改成“理解”):
模板1(概念优先):
我在学习【库/概念】。请先用 3 句话给出核心心智模型,再给 2 个常见误区与对应反例。不要直接给完整代码。
模板2(最小提示调试):
我遇到这个报错:{粘贴错误信息}
我自己的猜测原因是:{写你的假设}
请你只给“下一步该验证什么”的提示(最多3步),不要直接把代码改好。
模板3(生成后理解校验):
请为以下函数生成实现:{需求}
生成后请逐行解释关键行“为什么必须这样写”,并给出 2 个改动点:一个会引入 bug、一个会改变并发语义。我会用它来做自测。
模板4(把AI变成出题老师):
围绕我刚写的这段 Trio 代码,请出 5 个自测题(含 2 个调试题),并给标准答案与解释。
最后强调一个容易误判的点:论文数据显示,“手动抄 AI 代码”未必比“直接粘贴”带来更高测验分数;真正关键的是你有没有投入认知努力(解释、提问、独立排错)。因此,最有效的习惯不是“多敲键盘”,而是“强制复盘 + 强制自测”。
后续实验与验证建议
作者在论文里已经列出一组很合理的后续方向:换任务/换工具形态(agentic)、拉长时间尺度做纵向研究、提升参与者真实动机、显式测量提示词能力、用其他评估方式替代单次测验、加入“人类帮助”的对照(结对/课堂/代码评审)。
在此基础上,如果目标是把“交互税”和“技能退化机制”拆得更干净,我建议增加三类操控与验证:
第一,把“报错暴露度”当成自变量:例如同样使用 AI,但随机分组为“允许 AI 直接修复” vs “AI 只能解释错误,不能输出修复代码”,观察调试题差异是否收敛,从而更精确地检验“错误驱动学习”机制。
第二,把“交互摩擦”当成自变量:对比聊天式(高提示词摩擦)与 IDE 自动补全/代理(低提示词摩擦),检验作者的推断——摩擦越低,可能越容易完全外包,从而学习损失更大。
第三,引入“复现能力/迁移能力”指标:让参与者一周后完成一个新 Trio 任务或做一次代码审查(review 一段 AI 写的 Trio 代码并找 bug),比立即测验更贴合真实工作中的监督任务。
论文(arXiv PDF):
https://arxiv.org/pdf/2601.20245
论文(arXiv 摘要页):
https://arxiv.org/abs/2601.20245
Anthropic 研究博客(对论文的官方科普总结):
https://www.anthropic.com/research/AI-assistance-coding-skills
复现实验材料与数据(GitHub 仓库):
https://github.com/safety-research/how-ai-impacts-skill-formation
Trio 文档(任务背景库):
https://trio.readthedocs.io/en/stable/
预注册(OSF,论文内给出链接):
https://osf.io/w49e7
作者页面(可选):
https://scholar.google.com/citations?hl=en&user=LCjSZ3eS8pIC
https://www.alextamkin.com/