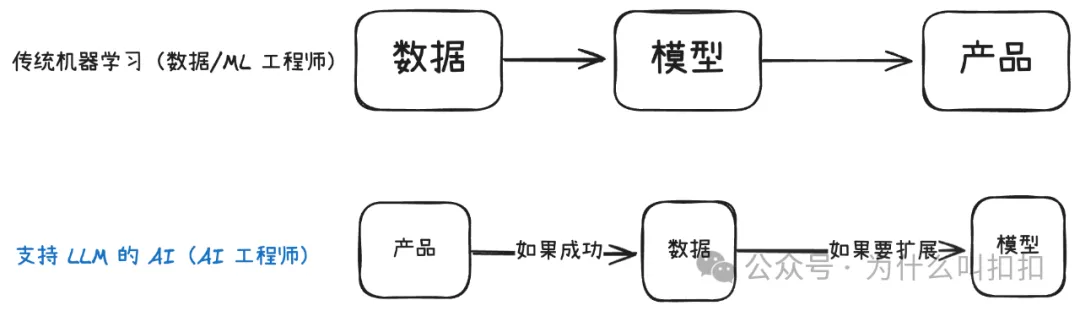
[译文]AI 工程师的崛起
随着AI新能力的不断涌现,一个全新的角色正逐渐成形。为了真正驾驭这些能力,我们必须走出“提示工程师”(Prompt Engineer)的框架,不仅要亲自编写软件,还要让 AI 也具备编写软件的能力。 我们正在见证一个百年难遇的 AI 应用“右移”浪潮(shift right),其动因是基础模型(Foundation Models)所带来的新涌现能力,以及这些模型在开源或可调用 API 形态下的广泛可用性。

![[译文]AI 工程师的崛起](/content/images/size/w2000/2025/01/640.webp)
随着AI新能力的不断涌现,一个全新的角色正逐渐成形。为了真正驾驭这些能力,我们必须走出“提示工程师”(Prompt Engineer)的框架,不仅要亲自编写软件,还要让 AI 也具备编写软件的能力。
我们正在见证一个百年难遇的 AI 应用“右移”浪潮(shift right),其动因是基础模型(Foundation Models)所带来的新涌现能力,以及这些模型在开源或可调用 API 形态下的广泛可用性。
在 2013 年,那些需要五年时间和一个研究团队才能完成的各种 AI 任务,如今在 2023 年只需翻阅一下 API 文档,并利用一个下午的空闲时间就能实现。
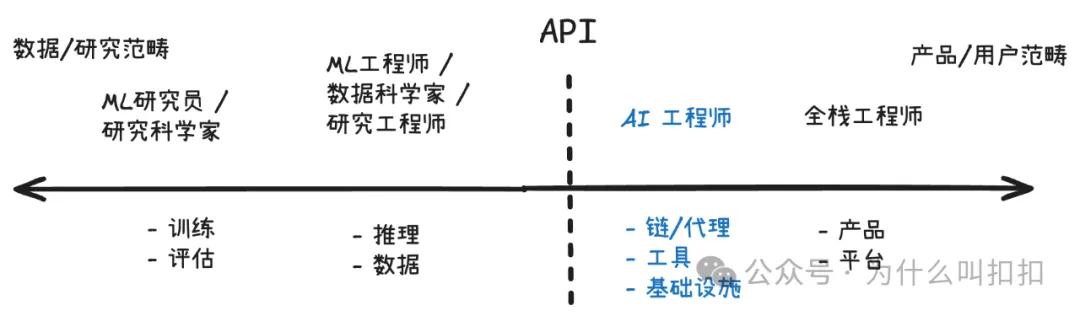
重要提示:图中的 “API” 这一分界并非不可逾越——AI 工程师也可能向左侧延伸,去微调或自建模型;研究工程师同样会向右侧拓展,基于 API 来构建应用!同时,这张图对于如何放置 “evals(评测)” 和 “data(数据)” 的做法也受到了批评;我们也认为评测在工作中非常重要。通常而言,ML 研究人员/工程师负责基础模型相关的工作,包括大规模预训练数据和通用基准评测;但 AI 工程师也应将面向产品的具体数据和评测视为自己的职责。
“从数量上来看,将来很可能会有更多的 AI 工程师,而不是 ML 工程师或 LLM 工程师。即便从未训练过的任何模型,也能在这一岗位上取得相当成功。”—— 安德烈·卡帕斯(Andrej Karpathy)"
然而,细节才是最难的——要成功评估、应用并产品化 AI,面临的挑战非常之多,例如:
- 模型:从评估 GPT-4 和 Claude 这样的大模型,到使用 Huggingface、LLaMA 等开源模型。
- 工具:从最流行的链式调用、检索及向量搜索工具(如 LangChain、LlamaIndex、Pinecone),到崭露头角的自治代理领域(如 Auto-GPT、BabyAGI,推荐阅读 Lilian Weng 的综合回顾)。
研究 / 进展:与此同时,每天都有海量新论文、模型和技术涌现,并伴随资金和关注度的指数级增长,想要完全跟上这些进展几乎需要投入全职精力。
我认为这确实是一份全职工作。我认为软件工程会催生一个新的分支学科,专门研究 AI 的应用,并有效地运用这些新出现的技术栈,就像“网站可靠性工程师”(SRE)、“DevOps 工程师”“数据工程师”“分析工程师”先后出现那样。
这个新兴角色(同时也是最不“尬”的称呼)大概率就是:AI 工程师(AI Engineer)。
我所知道的每一家初创公司都在 Slack 里有一个 #discuss-ai 频道。这些非正式的小组交流会慢慢变成正式团队,就像 Amplitude、Replit、Notion 已经做的那样。无论是在公司时间还是在夜晚和周末,无论是在企业 Slack 里还是独立的 Discord 频道里,数以千计的软件工程师都在为 AI API 和开源模型“投入生产化”而努力,他们最终会专业化并对外使用一个统一的头衔:AI 工程师。毫无疑问,这是本十年最具需求量的工程岗位。
从微软、谷歌等大型公司,到 Figma(通过收购 Diagram)、Vercel(例如 Hassan El Mghari 的爆红项目 RoomGPT)和 Notion(例如 Ivan Zhao 和 Simon Last 的 Notion AI)等前沿初创公司,再到像 Simon Willison、Pieter Levels(Photo/InteriorAI)以及 Riley Goodside(现就职于 Scale AI)这样的独立黑客,都不乏 AI 工程师的身影。他们在 Anthropic 做提示工程可以年薪 30 万美元,在 OpenAI 做软件构建则可以年薪 90 万美元。他们在 AGI House 利用空闲周末孵化点子,并在 /r/LocalLLaMA(https://www.reddit.com/r/LocalLLaMA/?rdt=42968) 分享心得。
他们的共同点在于:能把 AI 的最新进展迅速变成数百万用户的真实产品,几乎是一夜之间完成。
这里面看不到什么博士。 在上线 AI 产品时,你需要的是工程师,而不是研究人员。
AI 工程师 vs. ML 工程师的“反转”
我提到这一趋势并不是要“创造”它。实际上对 “ML工程师” 的职位需求可能是 “AI工程师” 的 10 倍,但 “AI” 一词的热度增速更快,让我相信这种比例会在 5 年内出现逆转。
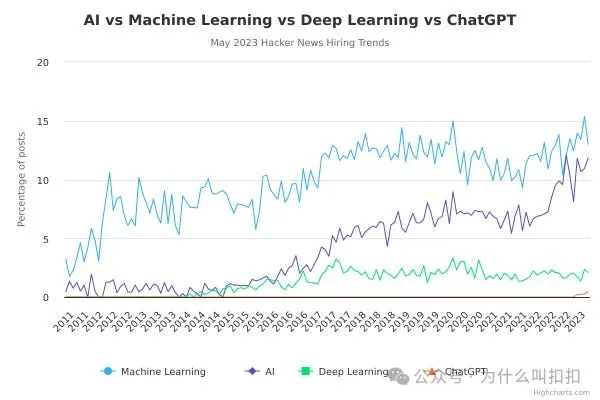
所有职位名称都有缺陷,但有些的确能发挥作用。我们对“AI”和“ML”之间无休无止的语义争论感到厌烦,也知道“软件工程师”这个角色本身就足以胜任大多数 AI 软件的构建需求。不过,最近有人在 Hacker News(https://news.ycombinator.com/item?id=36432598) 上提了个问题“如何进入 AI 工程化”,从高赞回答也能看出目前市场的主流认知:
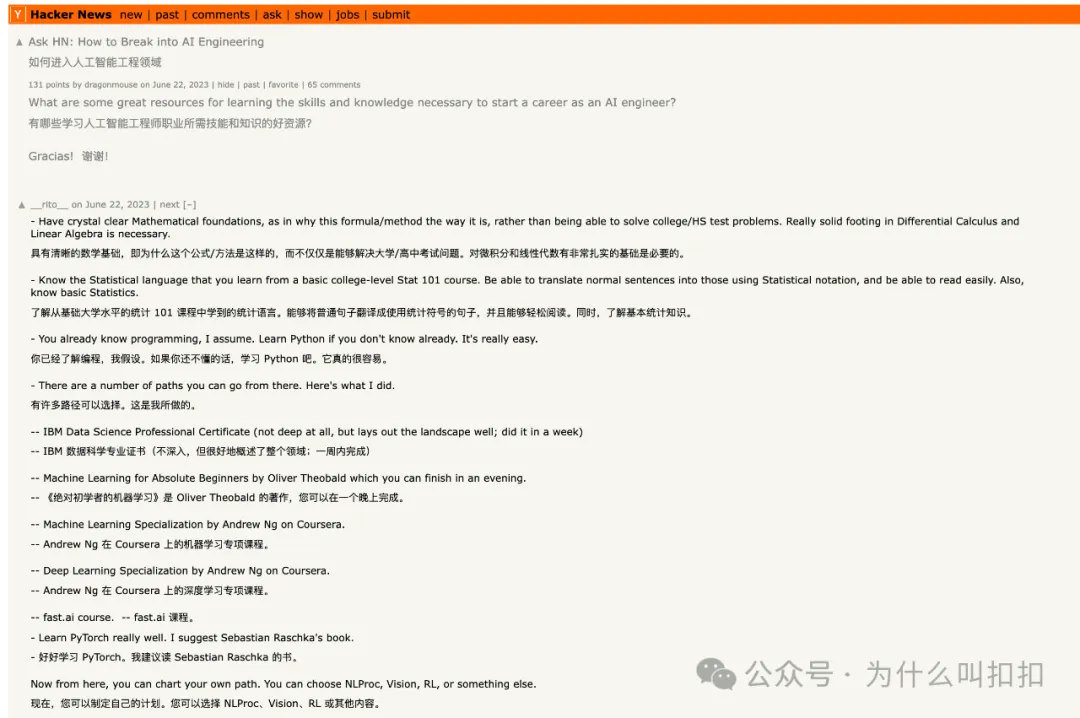

大部分人依然认为 AI 工程就是机器学习或数据工程的一种,所以推荐学习同样的先修知识。但我敢说,我前面提到的那些卓有成效的 AI 工程师,并没有全部做过“吴恩达 Coursera”课程,也不太懂 PyTorch,更不熟悉“数据湖”和“数据仓库”之间的区别。
在可见的未来,恐怕不会有人再建议你先看《Attention Is All You Need》来入门 AI 工程,就像没人会建议你通过研究福特 T 型车的详细结构图来学开车一样。当然,了解这些基础原理和历史背景永远是有帮助的,也能帮助你发现一些尚未被大众所熟知的效率或能力提升点。但有时候,你只需要使用并体验那些产品,就能了解它们的特性。
我也不认为这种“课程翻转”会一夜之间发生。人天生就喜欢在简历上填满各种内容,或者画满各种市场图谱,还想显得自己对更深层次的话题更有话语权。换言之,Prompt 工程或 AI 工程,对那些拥有扎实数据科学/ML 背景的人来说,短期内仍会“显得”比不上他们。但我相信,单纯从供需经济的角度出发,最终 AI 工程还是会大放异彩。
为什么 AI 工程师会在此时崛起?
- 基础模型是“少样本学习者”
它们表现出了上下文学习(in-context learning)甚至是零样本迁移的能力,这些能力可以超越最初模型训练者的预期。换句话说,模型的创造者自己也无法完全预料模型究竟能做什么。只要对模型花足够的时间并把它们应用到研究不太关注的领域(例如 Jasper 针对文案写作),就能找出并利用这些隐藏能力。而这些人并不需要是 LLM 研究人员。 - “AI 研究即服务”
微软、谷歌、Meta 以及大型基础模型实验室已经网罗了稀缺的研究人才,向外提供“AI 研究即服务”形式的 API。你无法直接雇到他们,但你可以“租”到他们的成果——前提是你的公司有相应的软件工程师,懂得如何有效使用它们。全世界可能只有大约 5000 名 LLM 研究人员,但有大约 5000 万软件工程师。供需关系表明必然会出现一个“中间层”的 AI 工程师群体来应对需求。
GPU 囤积
OpenAI/Microsoft 最先行动,Stability AI 也开启了初创公司 GPU 军备竞赛,宣称他们拥有一个 4,000 GPU 的集群。
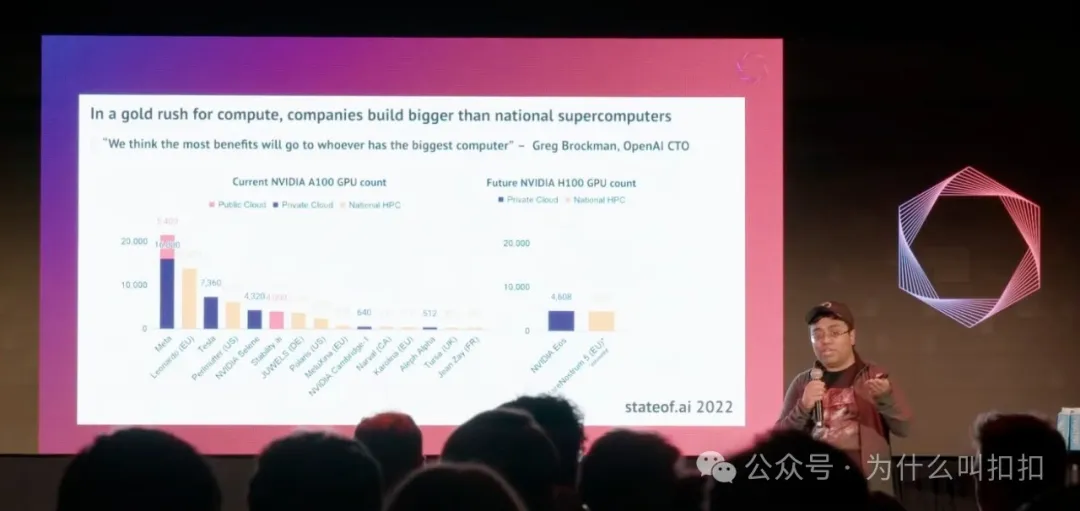
如今,新成立的初创公司如 Inflection(融资 13 亿美元)、Mistral(1.13 亿美元)、Reka(5800 万美元)、Poolside(2600 万美元)、Contextual(2000 万美元),都会在种子轮阶段大举融资,用来购买自己的硬件。Dan Gross 和 Nat Friedman 也宣布了 Andromeda,这个总计 10 exaflop、价值 1 亿美元的 GPU 集群只对他们投资的初创公司开放。全球芯片短缺反过来又加剧了这种抢购潮。于是,对 API 端有巨大需求的 AI 工程师会比真正能训练模型的专家多得多。
“先开火,再瞄准”
传统做法往往需要数据科学家/ML 工程师先耗费大量时间收集数据,再训练出一个特定领域的模型,最后才能投入生产。而现在,产品经理/软件工程师可以先用 LLM 做 Prompt,就能快速验证产品想法,然后再去收集特定数据做微调。
如果说后者(先 prompt 后收集数据)的人群比前者要多出 100-1000 倍,而且这种流程速度能比传统 ML 快 10-100 倍,那么 AI 工程师验证产品想法的成本可能就只有以前的 1/1000 到 1/10000。这就像“瀑布式”方法和“敏捷”方法之间的对比。AI 是敏捷的。
Python + JavaScript
数据/AI 传统上高度依赖 Python,像 LangChain、LlamaIndex、Guardrails 这些早期 AI 工程工具也大多出自 Python 社区。然而,现在至少有与 Python 数量相当甚至更多的 JavaScript 开发者,因此越来越多的工具开始服务这部分人群,比如 LangChain.js、Transformers.js,以及 Vercel 最新推出的 AI SDK。潜在市场直接增加了一倍。
生成式 AI vs. 分类式机器学习
虽然“生成式 AI(Generative AI)”这一术语的热度在下降,被“推理引擎”等各种新说法所取代,但它还是能用来大致描述现有“ML 工具/从业者”和那些采用文本图像生成器、最佳使用 LLM 的“新一代人群”之间的差异。之前的 ML 往往专注于欺诈检测、推荐系统、异常检测、特征存储,而 AI 工程师们在做写作应用、个性化学习工具、自然语言电子表格,以及类似《异星工厂》(Factorio)风格的可视化编程语言。
当一个子群体拥有完全不同的背景、使用不同的语言、创造截然不同的产品,并且用上一整套不一样的工具时,他们最终就会自成一个新群体。
1+2=3: 从 Software 2.0 到 Software 3.0:代码在演进中的角色
六年前,Andrej Karpathy 写过一篇很具影响力的文章,阐述了“Software 2.0”的概念,比较了“经典软件栈”(通过人工编写编程语言来准确建模逻辑)和“机器学习”神经网络栈(通过近似逻辑来解决人类无法硬编码的更多问题)。今年他又补充说当下最热门的“编程语言”就是英语,让我们注意到他在那篇文章的插图里留白的区域,现在正被填补。
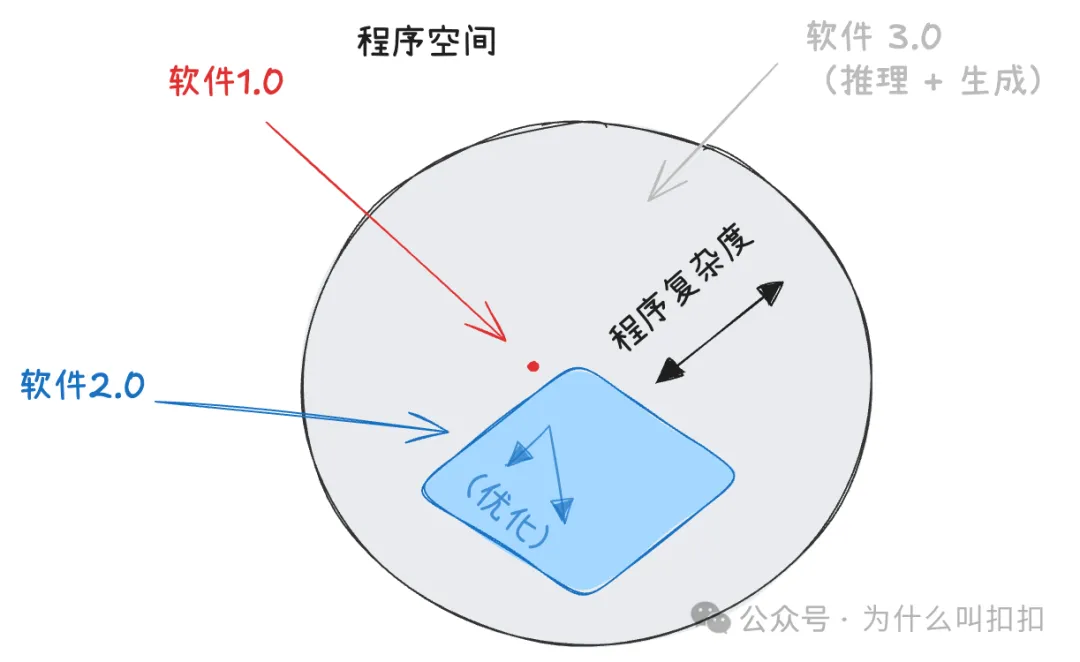
去年,“提示工程”(Prompt Engineering)因为 GPT-3、Stable Diffusion 的实际应用而走红。人们嘲笑那些仅仅把 OpenAI 封装一下的 AI 初创公司,担心 LLM 应用会被 Prompt 注入和反向提示工程轻易攻破。难道就没有护城河可言吗?
但 2023 年的一大主题,就是重新确认人类书写的代码在利用 LLM 的能力时所扮演的角色——无论是市值超过 2 亿美元的 LangChain,还是英伟达投资的 Voyager 都表明,代码生成和复用无可替代(我最近和 Harrison 一起参与了一个名为“Chains vs Agents”的线上研讨会,讨论了“代码核心 vs. LLM 核心”应用的观点)。

Prompt 工程可能被过度吹捧,但它也将继续存在。而软件 1.0 范式在 Software 3.0 应用中的重新崛起,既是一个巨大的机遇和迷茫的来源,也为大量新创公司创造了空白市场空间:
当然,并不仅仅是人类编写的代码。我最近在 smol-developer、gpt-engineer、以及 Codium AI、Codegen.ai、Morph/Rift 等代码生成代理上做的实验,也让我相信这些工具将越来越成为 AI 工程师的标配。随着人类工程师逐渐学会驾驭 AI,AI 也将越来越多地从事工程工作,直到某一天我们恍然发现我们早已分不清彼此的界限。
原文:https://www.latent.space/p/ai-engineer